- # Model version
- ** Lighting Attention mechanism**
- ** Super-long context **
- Training costs
- MiniMax-M1 Performance
- I’ll be right back
- 1. ** Mathematical and logical reasoning**
- # 6. ** Dialogue and assistant capabilities**
- # 7. ** Weakness: less ability to question and answer facts**
- MiniMax-M1 Technological innovations and bright spots
- # Structural innovation: ** Mixed Attention Mechanism**
- # Enhanced learning training optimization: ** New RL algorithm CISPO**
- # All-round enhancement of reasoning: ** with advantages in multiple and complex tasks**
- # Engineering efficiency optimizes
- Function Calling + Tool Use
MiniMax released MiniMax-M1, the first global ** Open Source** large-scale mixed attention reasoning language model. The main features of this model are the integration of **Mode (MoE) and efficient Lighting Attention mechanisms, which have significant advantages in the speed of reasoning, long text processing and performance of complex tasks.
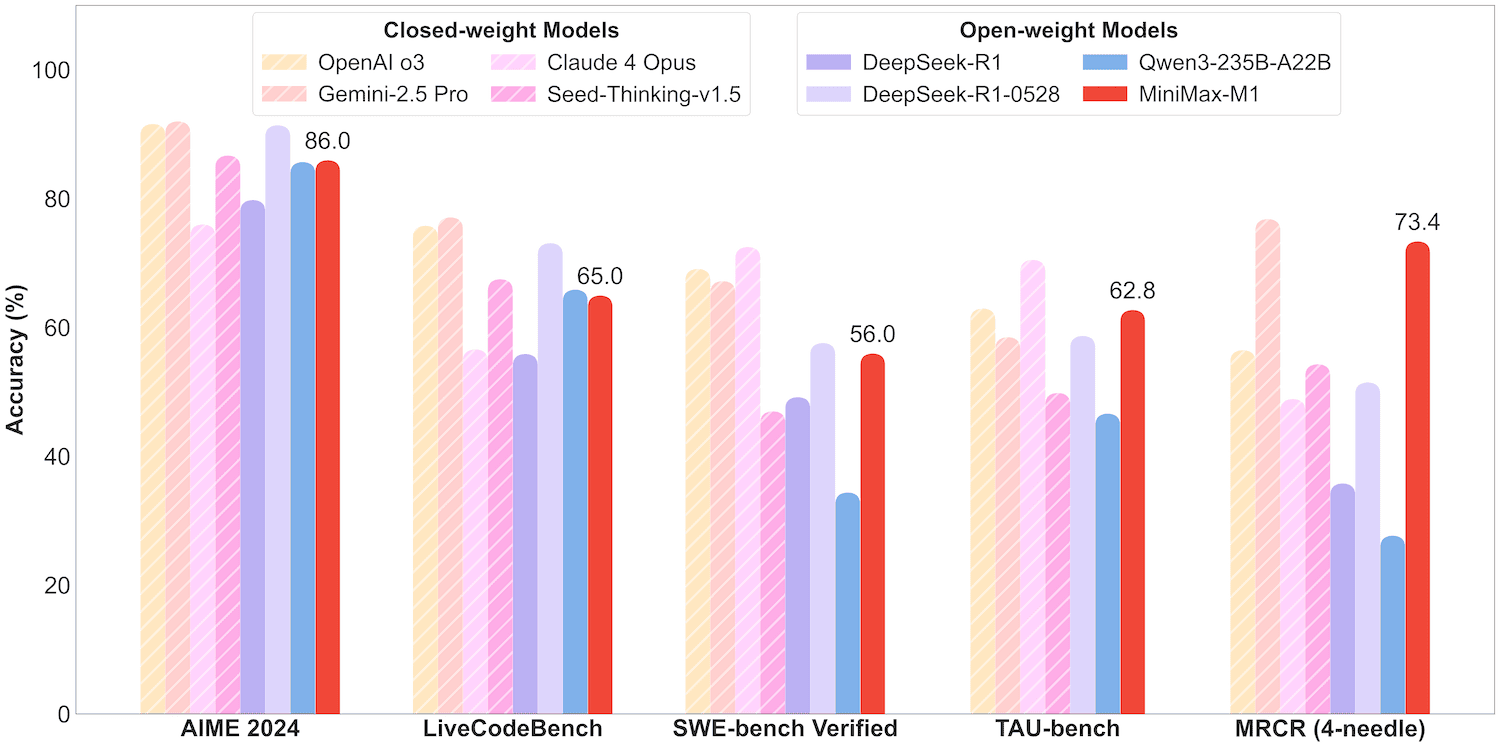
In most missions, MiniMax-M1 ** is significantly superior to other open-source large models (e.g. Qwen3, DeepSeek-R1)** and is approaching or even partially exceeding commercial closed-source models.

# Model version
MiniMax-M1-40K: Context: 1 million MiniMax-M1-80K: Context: 1 million
** Mixed expert model (Mixture-of-Experts, MoE)**
-
Every token activates about 4.590 billion parameters (456 billion total parameters), using only some experts to improve the efficiency of reasoning.
-
Balanced the contradiction between “large model capabilities” and “landable deployments”.
** Lighting Attention mechanism**
-
An optimised approach to attention devoted to the large-scale context**.
-
MiniMax-M1 was calculated at only 25 per cent of the 100,000 tokens generated tasks compared to models such as DeepSeek R1.
** Super-long context **
- The background of 1 million token, far more than most of the same models (e.g. DeepSeek R1 supports 128K).
Training costs
-
RL intensive training only takes 3 weeks + 512 H800 GPU
-
** Total cost is only $5.35 million**
MiniMax-M1 Performance
I’ll be right back
1. ** Mathematical and logical reasoning**
-
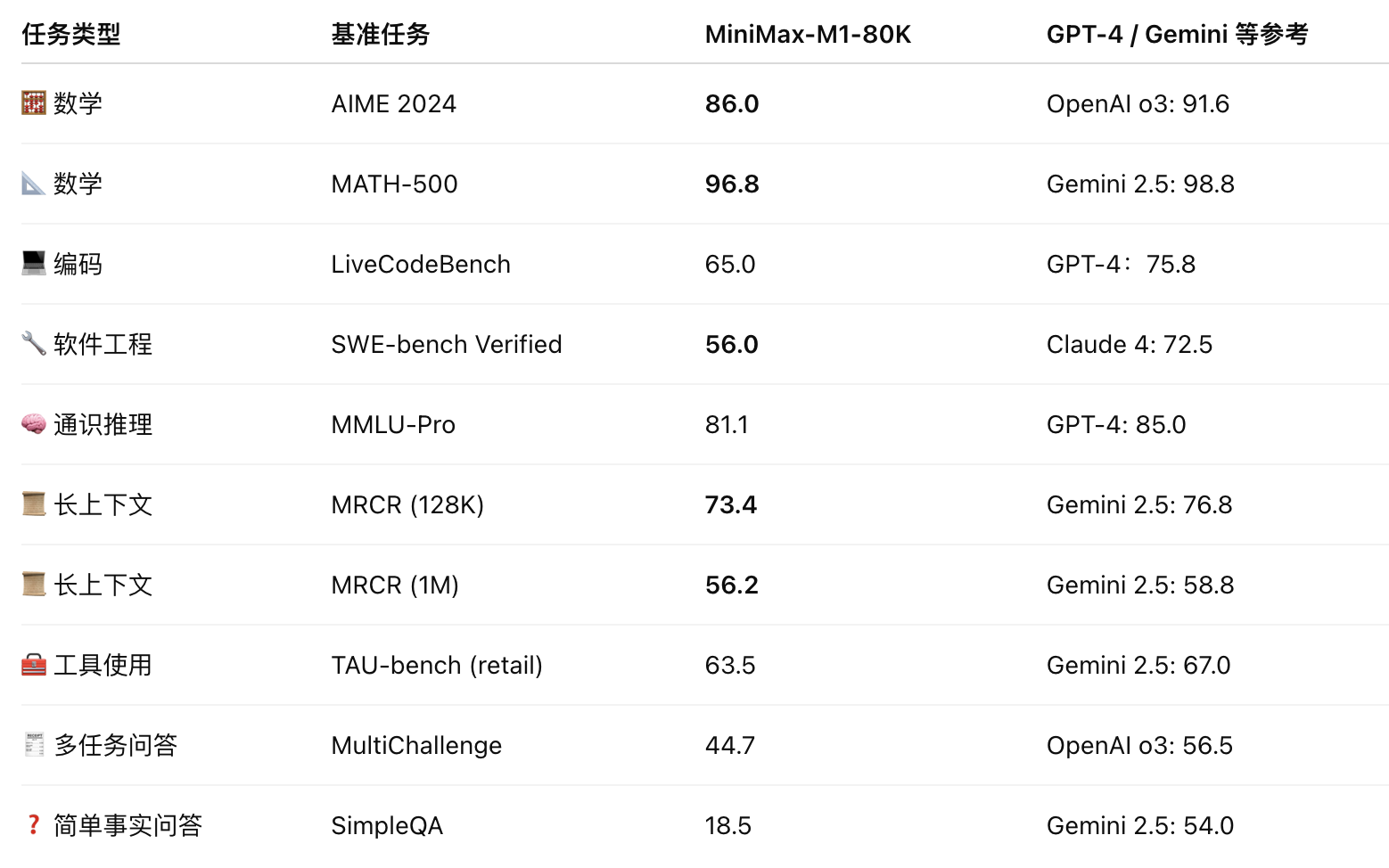
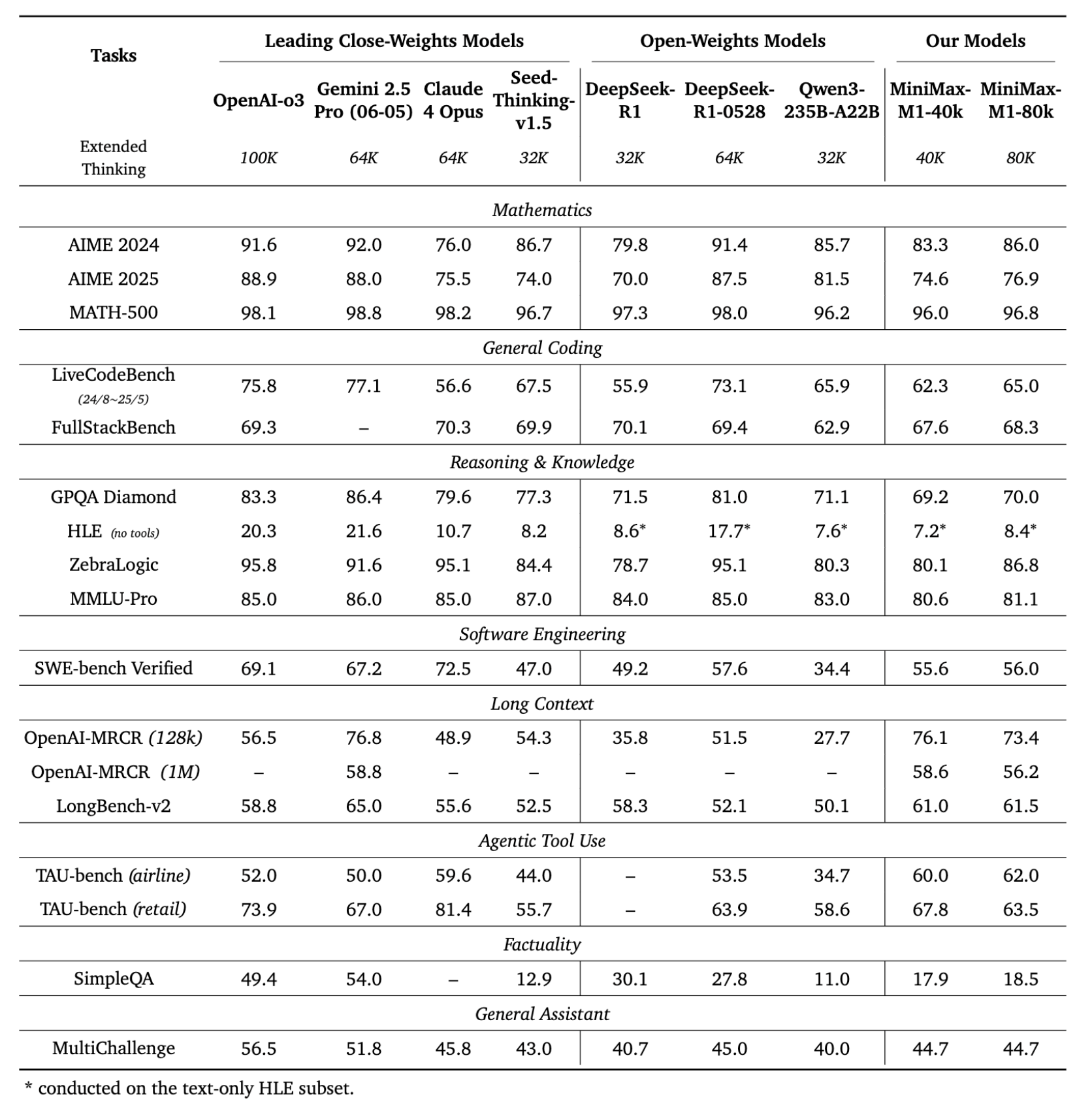
High score in AIME 2024 competition 86.0%
-
near-full (96.8%) at MATH-500
-
Demonstrating excellent thinking in the chain (Chain-of-Thought)
-
The SFT + RL phase sharpens the path of reflective reasoning
- General and advanced programming tasks
-
Covers from LiveCodeBnch to FullStackBnch
-
Demonstrate a comprehensive understanding of the syntax, logic and structure of the code
-
Stable performance, suitable for code generation or smart IDE integration
3. ** Real software engineering tasks**
-
SWE-bench: Validation model for bug restoration and PR submission automatically based on real GitHub problems
-
MiniMax-M1 constructed the real sandbox system and validated it at the code implementation level
-
Score 56%, stronger than all open-source models, after the latest closed-source model
4. Super-long text capability
-
Support 1 million tokens context (original support)
-
The performance of the MRRCR, LongBnch, etc.: **MRCR-128K score 73.4% **: closer to real understanding than GPT-4
-
Capable of handling complex instructions, legal documents, scientific documents, etc.
5. Agent Capabilities: Tool Use and Call
-
TAU-bench simulation real API use scene
-
MiniMax-M1 over Gemini 2.5 and Claude 4:30. Airline: 62%
-
Retail: 63.5%
It shows that it has a strong ability to adapt to complex reasoning and motion-driven intelligent tasks.
# 6. ** Dialogue and assistant capabilities**
-
MultiChallenge score of 44.7%.
-
Same as Claude 4, DeepSeek-R1
-
Be stable in multi-mission dialogues, suitable for use as a base model for assistants
# 7. ** Weakness: less ability to question and answer facts**
-
18.5% on SimpleQA, indicating: Accurate answers to short, clear questions and room for improvement.
-
Related to training data distribution or incentive model preferences
MiniMax-M1 Technological innovations and bright spots
# Structural innovation: ** Mixed Attention Mechanism**
- Righting Attention + Softmax Attention
-
Lighting Attention is a linear complexity attention mechanism, replacing the traditional Quadratic approach, which is more slowly calculated with the length of the text.
-
Inserting 1 layer of Softmax Attention per 7 layers to enhance modelling capabilities in context.
-
Advantages: Support context input for 1,000,000 tokens
-
Significant reduction in the number of reasoning calculations (e.g., FLOPs are only 25% of DeepSeek R1 when 100K tokens are generated)
Model size and computational efficiency: Mixture of Experts (MoE) Mixed Expert Mechanism
-
The total parameters of the model amount to 45.6 billion, activated only 45.9 billion (i.e. about 10%)
-
Used 32 specialist modules, activated in each input selection part
-
Advantages: ** Calculating efficiency: use of only some parameters for reasoning without loss of capability, significant reduction in reasoning and training costs**
-
Extensible: Total parameters can be extended to 100 billion grades without compromising the cost of use.
-
** Fine-tuning**: Only local experts are optimized and the field is also well suited.
-
Maintaining the performance of the large model while applying to multitasking schedules
# Enhanced learning training optimization: ** New RL algorithm CISPO**
Problems: Traditional methods like PPO, GRPO have token branch cutting problems that ignore key turning points in reasoning (e.g., “wait, think again …”) Solution: MiniMax proposed CISPO (Clipped IS-Weight Policy Implementation)
-
Amend to read “Cut sample weights”, ** to retain all tokens training signals**
-
Advantages: Keep a rare but important line of reasoning
-
Training is more stable and efficient.
-
Training speed increases in comparison with GRPO, DAPO 2 times
# All-round enhancement of reasoning: ** with advantages in multiple and complex tasks**
-
Super long text processing: support 1M input, 80K output, suitable for scientific papers, legal instruments, etc.
-
** Complex task reasoning**: excellent performance in AIME Mathematics, LiveCodeBnch programming, SWE-Bench software engineering tasks
-
Toolability: In TAU-bench, over Gemini 2.5 Pro, Claude 4, fit to build complex intelligence
# Engineering efficiency optimizes
-
RL training only takes 3 weeks + 512 H800 GPU
-
** Total cost is only $5.35 million**, which is significantly lower than the cost of training in closed-source models such as GPT-4
-
** Logic and training have cost advantages** and contribute to model landing and popularization
Function Calling + Tool Use
Innovation point:
-
The built-in function call (Function Calling) module supports the output structured call parameters.
-
A complete tool call evaluation (TAU-bench) was built for Agent
Strengths:
-
Without additional fine-tuning, the model can identify when to call the tool and generate the parameter format;
-
Support the construction of search-enhanced Agent, task assistant, API interactive robots.
GitHub: https://github.com/MiniMax-AI/MiniMax-M1 Models: https://huggingface.co/collations/ MiniMaxAI/minimax-m1-685002ad96634ec0eac8cf094 Papers: https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf Online experience: https://chat.minimax.io/