- Core characteristics detailed
- 1. Fluid recognition: listening to text and going around
- 4. High co-opportunities
- Core technical principles: Delayed Flow Modeling
- Model advantage summary
** Kyutai STT** is an open source model developed by the Kyutai team for the optimization of the scene ** real-time speech-to-text, with the main features of ** low delay, high accuracy, strong co-processing capacity.
** Kyutai STT** Not only can be written with low delay, but also designed specifically for high-synchronous and real applications (e.g. voice dialogue systems) with ** semantic-level speech activity detection** capability.
-
kyutai/stt-1b-en_fr: English + French, low delay, suitable for interactive applications.
-
kyutai/stt-2.6b-en: English, greater and more accurate, applicable to scenarios where accuracy is very demanding.
Prior introduction Kyutai has launched Unmute: it can be inserted into any model, giving voice to any model iaoHu.AI College Kyutai XiaoHu. AI has launched Unmute, a highly modular voice AI system that can quickly add voice functions to any text large language model (LLM). That is, it can be inserted into any model, giving voice to the model. Unmu…https://www.xiaohu.ai/c/xiaohu-ai/kyutai-unmute![https://assets-v2.circle.so/bmwwuzlqoxlm4m7xtttlqyqo]
Core characteristics detailed
1. Fluid recognition: listening to text and going around
Kyutai STT supports ** real fluid voice recognition**, i.e.:
-
Audio-side input and processing without waiting for the end of the entire segment;
-
Real-time return of transpositions containing ** punctuation symbols and word-for-word time stamp**;
-
Accuracy of identification in comparison with non-current models (e.g. Whisper) can still be maintained at low delay.
This is critical for real-time voice assistants, live caption generation, meeting transcription, etc.
-
** Based on: speech content and synonym** (rather than silence);
-
Be able to adapt to different speech styles and be more intelligently “judge whether or not it is the turn of the system to respond”;
-
The experiment significantly enhances the natural nature of the dialogue and avoids interruption or non-response for long periods of time.
Once upon a time: the system thinks you’re finished. ** Question **: People sometimes pause to speak out, such as “I want to eat the hot pot”, and the system may misjudge you. ** Now: Kyutai STT uses AI to judge the semantic and semantic tone of your speech and to be wiser to judge “Are you really finished” and to be more accurate.
#3. Very low delay
-
st-1b-en_fr: delay 500ms
-
st-2.6b-en: Delay 2.5 seconds (save part of real time to improve accuracy)
** “Flush technique”**: To further reduce the delay in response, Kyutai used a “accelerated flushing” mechanism:
-
Trigger the model immediately after the user’s speech has been tested** to speed up the processing of the remaining voice**
-
The model completes the final part of the audio process at 4 times real speed, only ~125ms
-
The effect is to bring the voice system’s response closer to instantaneous.
4. High co-opportunities
Moshi is particularly suitable for large-scale deployment, with the core advantage that its model structure allows natural co-processing:
-
Supportable on NVIDIA H100 GPU 400 simultaneous voice flow processing
-
Much more efficient than traditional models such as Whisper, which requires complex collage (e.g. Whisper-Streaming) and does not support batching, which has a low capacity for vomiting
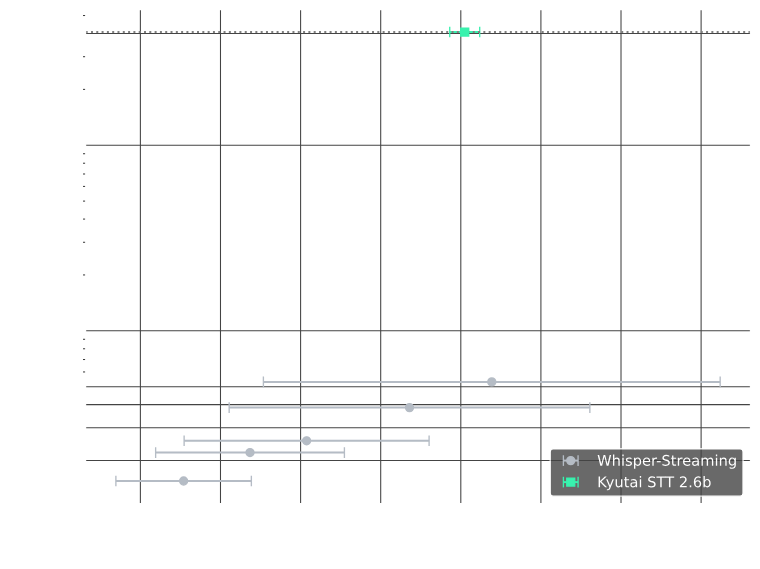
##5. Multiplatform support Kyutai provided several platforms to adapt to different use scenarios: Achieve platform application scenario PyTorch research and experiments Easy to call Rust production deployment in Python environment Stable and performance strong to support WebSocket MLX (Apple) iPhone/ Mac speed up with Apple hardware
Core technical principles: Delayed Flow Modeling
This is a new approach that is different from the traditional Encoder-Decoder, with the following core ideas:
-
View voice and text as ** two-time data streams**;
-
Text flow is “delayed” by several time frames, allowing the model** to see the sound of the next point** in order to improve accuracy;
-
Audio flow remains unchanged, and model learning on how to “fill” the corresponding text over time from the audio stream;
-
Modality in reasoning, without the need for full audio;
Another advantage of this modeling approach is expansionability:
-
TTS (synthesis of speech) can be achieved only by adjusting the flow order and alignment;
-
The current team is developing the Text-to-Speech model based on this structure.
Model advantage summary
Feature Description ** Low Delay ** Fast 500ms suitable for real-time voice interaction ** High Precision ** Close to or even superior to non-fluent models ** High Synergy ** Support hundreds of paths and flow processing suitable for deployment ** Semantic VAD** Determining whether speech ends with more intelligent and natural ** Multi-platform support** Support for scientific research, production and mobile end deployment
Online experience: Unmute - real-time voice conversation
-
Model file: kyutai/stt-1b-en_fr@Huging Face
-
kyutai/stt-2.6b-en @Huging Face
Source address: https://github.com/kyutai-labs/delayed-streams-modeling Official presentation: https://kyutai.org/text/stt