- FLUX.1 Kontext Target:
- Kontext, what’s the bright spot?
- Model version:
- Main function
- # 4. Iterative Edition
- # 5. Low Latency Infence
- How’s the evaluation going? Is the performance leading?
- They’ve also launched an interactive interface
- FLUX Playgroup Introduction:
- Current restrictions and concerns
A new generation of ** multi-modular image generation and editing models launched by Black Forest Labs: FLUX.1 Kontext, unlike the traditional text-map model, Kontext understands ** text and image input to achieve true ** context generation and editing. Traditional **text-to-image (text generation image) models, such as DALL E, Stable Diffusion, although powerful, have many limitations:
-
Only by word control, which does not allow for a flexible combination of pictures as context;
-
The inability to continuously edit or retain character features and the lack of “cognitive continuity”;
-
Local editing requires complex masking or ginturing;
-
Frequent deterioration of images after multiple rounds of operation (frustration, loss of style);
-
Slow editing and failure to meet real-time interactive needs.
FLUX.1 Kontext Target:
Builds an image generation and editing engine that really Context-aware. In other words:** you can naturally control image generation and modification with “Chart + Text” like Photoshop + GPT, be flexible, efficient, and keep people and style consistent.** It’s about:
-
The ability to understand the image context (not only to generate the image from the text, but also to understand it and modify it)
-
** Rapidly interactive editing capacity** (low delay, step-by-step)
-
Role consistency, local editing, style migration, etc.

Kontext, what’s the bright spot?
Coherence of roles: Consistency of persons or elements can be maintained in multiple scenarios ** Partial editing: editing only specific parts of the image, without prejudice to other regions ** Style reference: new scenes can be generated in specified styles ** Rapid interaction**: rapid rotation, extremely low delay
Model version:

-
FLUX.1 Kontext [pro] Fits for fast-track iterative editing to support continuous editing, maintaining consistency of roles, identities, styles and features in multiple scenarios
-
FLUX.1 Kontext [max] High-performance version with greater ability to follow hints, better layout performance and consistency
-
FLUX.1 Kontext [dev] Open source weight version of our state-of-the-art image editing model is currently in ** private beta**
Main function
1. Text + Image Prompt
Images can be generated not only by text, but also by uploading images and modifying them with text.


2. Local Edition
-
It can be ** accurate to modify a part of the image** without affecting the overall style or other area.
-
There is no need for masking, stratification or image labelling.
This means that:** You can, like a mechanic, just “move wherever you want.”**

#3 3. Consistency between character and style (Character & Style Consistency)
-
Regardless of how many different scenes you generate, the model automatically maintains the person’s face, face and posture, provided that the same reference map or description is provided.
-
A uniform expression of style (e.g., cartoons, writings, water colours) can also be maintained.
The visual content used to construct continuous content (e.g. comic characters, virtual spokespersons) is very valuable.



# 4. Iterative Edition
-
You can change it over and over again to the same figure: “Let her laugh first, then put on the sunglasses, then change the background, then change the clothes.”
-
Each step of change is based on the retention of the previous round.
This is the first model system that allows multiple rounds of natural language to drive visual modification.

# 5. Low Latency Infence
-
8 times as fast as the current mainstream model;
-
Close to “real-time feedback” can be achieved during editing and generation, which is suitable for fast test errors and adjustments by users.
How’s the evaluation going? Is the performance leading?
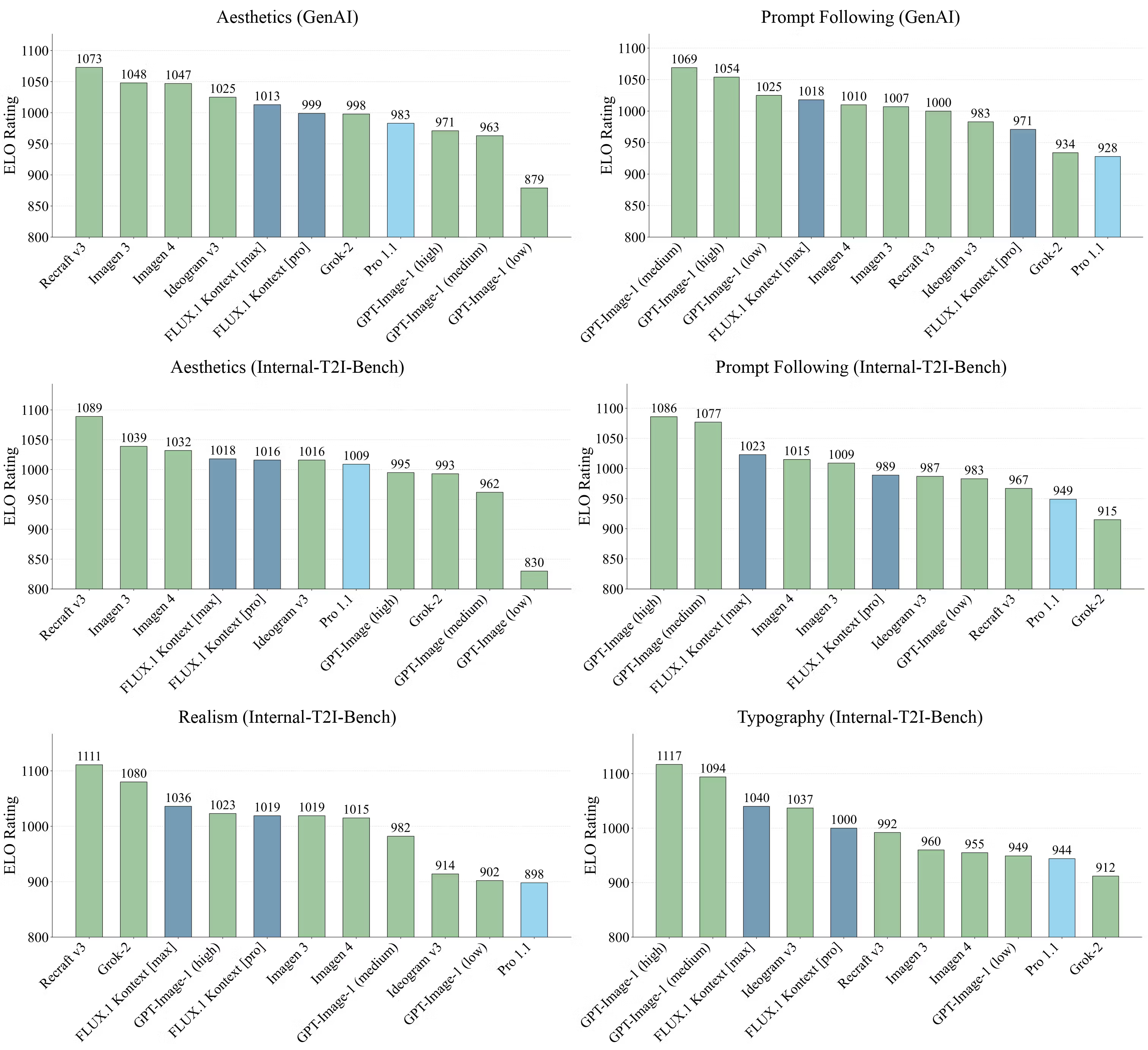
Black Forest Labs has proposed a new test set: KontextBnch to measure the modelling capability of the image task in context driven. The FLUX.1 model has a leading performance in six dimensions : ** Accuracy of text-guided editing ** Image authenticity is consistent with style** ** The image of the role remains unchanged in multiple images** ** Chart layout and content fit** ** Stability in multiple rounds of editing** ** Speed of response and efficiency of reasoning** The results showed that:
They’ve also launched an interactive interface
FLUX Playgroup Introduction:
A ** graphical interface platform for developers, creators**, which does not require any code or integration, allows for the rapid use of the FLUX model. Characteristics:
-
Enter text or upload images and experience the generation and modification of effects in real time;
-
Multiple rounds of editing can be performed to see the comparison of each step;
-
A prototype and capability demonstration to be presented to clients or decision makers;
Address: https://playground.bfl.ai/
Current restrictions and concerns
BFL also honestly lists the current model limitations:
-
The possible deterioration of the quality of the image (e.g., colour pseudo-portrait, vague details) after several consecutive revisions;
-
In individual cases, the model ‘ s interpretation of the text deviates from or ignores certain requirements;
-
A weak understanding of “world knowledge” (e.g., the possibility of creating an unstructured scenario);
-
Some details may be lost during the model compression distillation process (impact on high authenticity applications).
This suggests that it** is better suited to the needs of graphic creativity, conceptual drawings, product prototypes, landscape mapping, etc., rather than the final stages of fine-tuning.** ** Official presentation: * https://bfl.ai/announsets/flux-1-kontext ** Technical report:** Read the full tech report