- Main functional characteristics
- Maximum light: act like a sounding actor
- # Native multilingual support (globalization)
- How to achieve quality?
- # The model structure and reasoning optimizes
- ** Multiple indicators lead the world: **
- The price is very low, available to everyone
- How do you experience it?
OpenAudio announced the release of the latest speech-generation model - S1 model, with the goal of ** achieving the performance and nature of a professional voice actor. The model was developed by the Hanabi AI research laboratory and released through the product platform ** Fish Audio. S1 has:
-
High natural, fluid sound.
-
A rich tone and emotional control.
-
Strong command follower
Its training data exceed 2 million hours of audio, with model parameters as high as 4 billion (S1), a landmark product.
** Model version**

Main functional characteristics
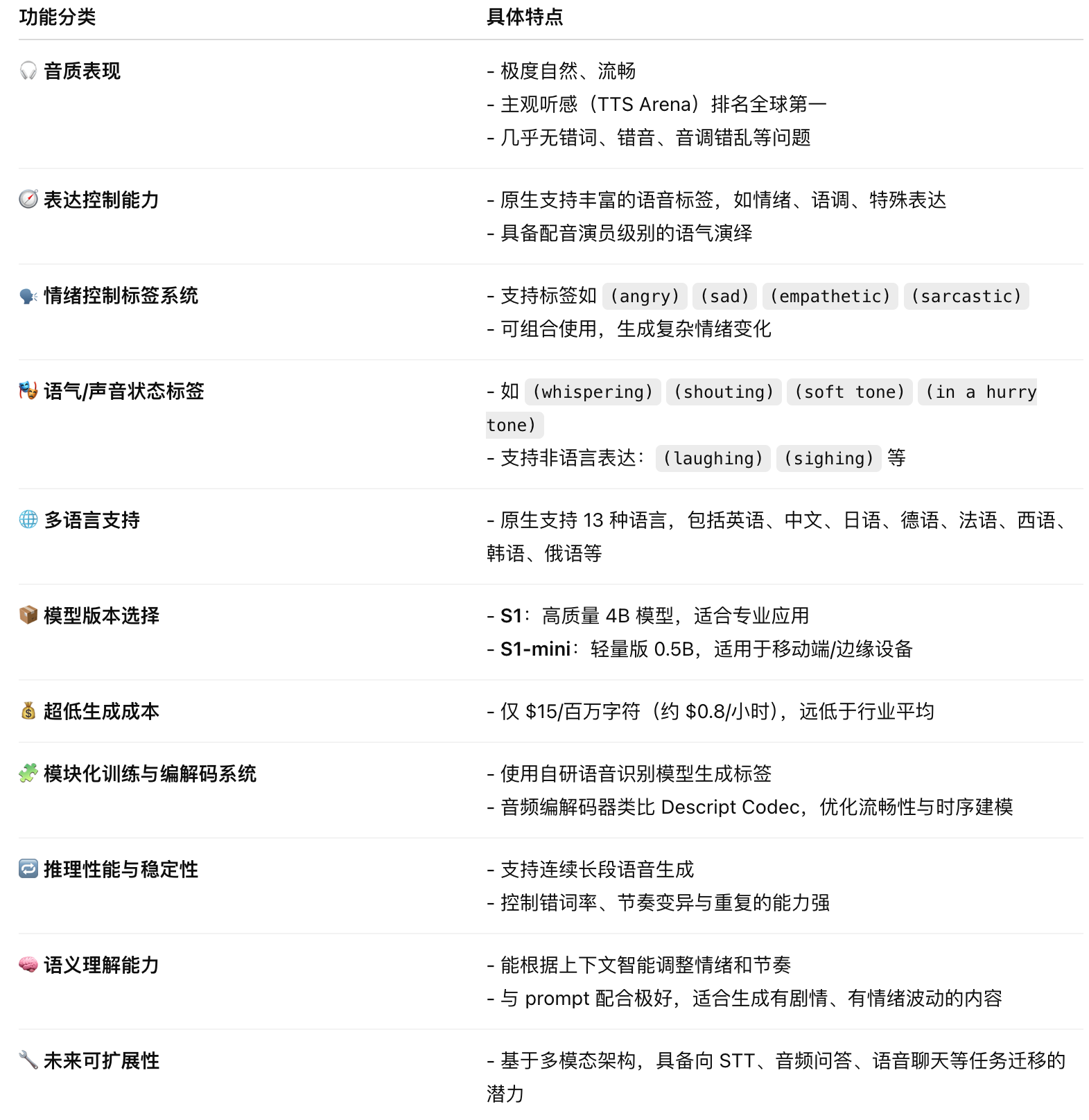
Maximum light: act like a sounding actor
The greatest innovation of S1 is that it understands and plays “** the emotions and tone of the person who speaks”, just like a professional voicewriter. ♪ How did it do it? ♪ OpenAudio first trained a self-researched **Stt) to automatically recognize voice:
-
Emotions (e.g. grief, anger, joy, common sense, sarcasm, etc.)
-
Voice (e.g. rush, whisper, shout, scream, etc.)
-
Talker’s character information.
Then, using these voice tags, more than 100,000 hours of voice data was marked as S1 training input.
** Supported voice control tag:**
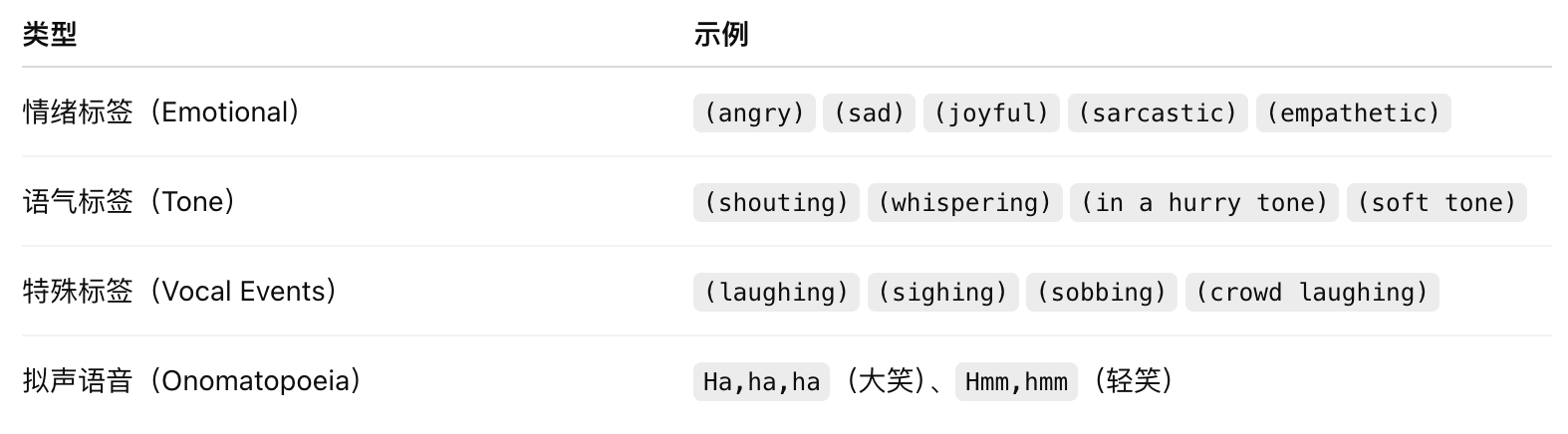
- Emotional Markers: e. g. (angry) (sad) (joyful) (sarcastic) (empathetic) et al.
- Tone Markers: (in a hurry tone) (whispering) (souting) (soft tone)
- Special Markers:
(lugging) (sighing) (crowd laughing)
Support** word-marking: e.g. Ha, ha, ha Hmm, hmm
These functions are derived from OpenAudio’s self-researched ** Emotional Voice Recognition STT Model, which can automatically mark the voice, emotion, tone, etc. of the audio and further enhance the TTS command understanding and restoration capability.
These labels can be inserted into the text to guide AI to synthesize expressions of expression. For example:
Honey, what’s wrong?
I just said good bye to Sanjay.
# Native multilingual support (globalization)
S1 Provides original support in the following languages to ensure consistency in voice output for global applications:
English, Chinese, Japanese, German, French, Spanish
- Korean, Arabic, Russian, Dutch, Italian, Polish, Portuguese
How to achieve quality?
S1 high performance from the following key designs: ** Data and training strategy:**
-
2 million hours of audio data (one of the largest industries)
-
Self-research reward model used to optimize performance
-
Intensible online learning RLHF (using GRPO algorithms): used to fine-tune models to enhance sound authenticity and hearing quality
# The model structure and reasoning optimizes
-
Structure: based on Qwen3 multi-model architecture, supporting future expansion to audio question and answer, text and voice recognition tasks (currently only TTS functionality is open)
-
Audio decoding: Self-research Descripto Audio Codec system + Transformer structure
-
Optimizing technology: Optimizing voice performance using online RLHF for enhanced learning (based on GRPO strategy)
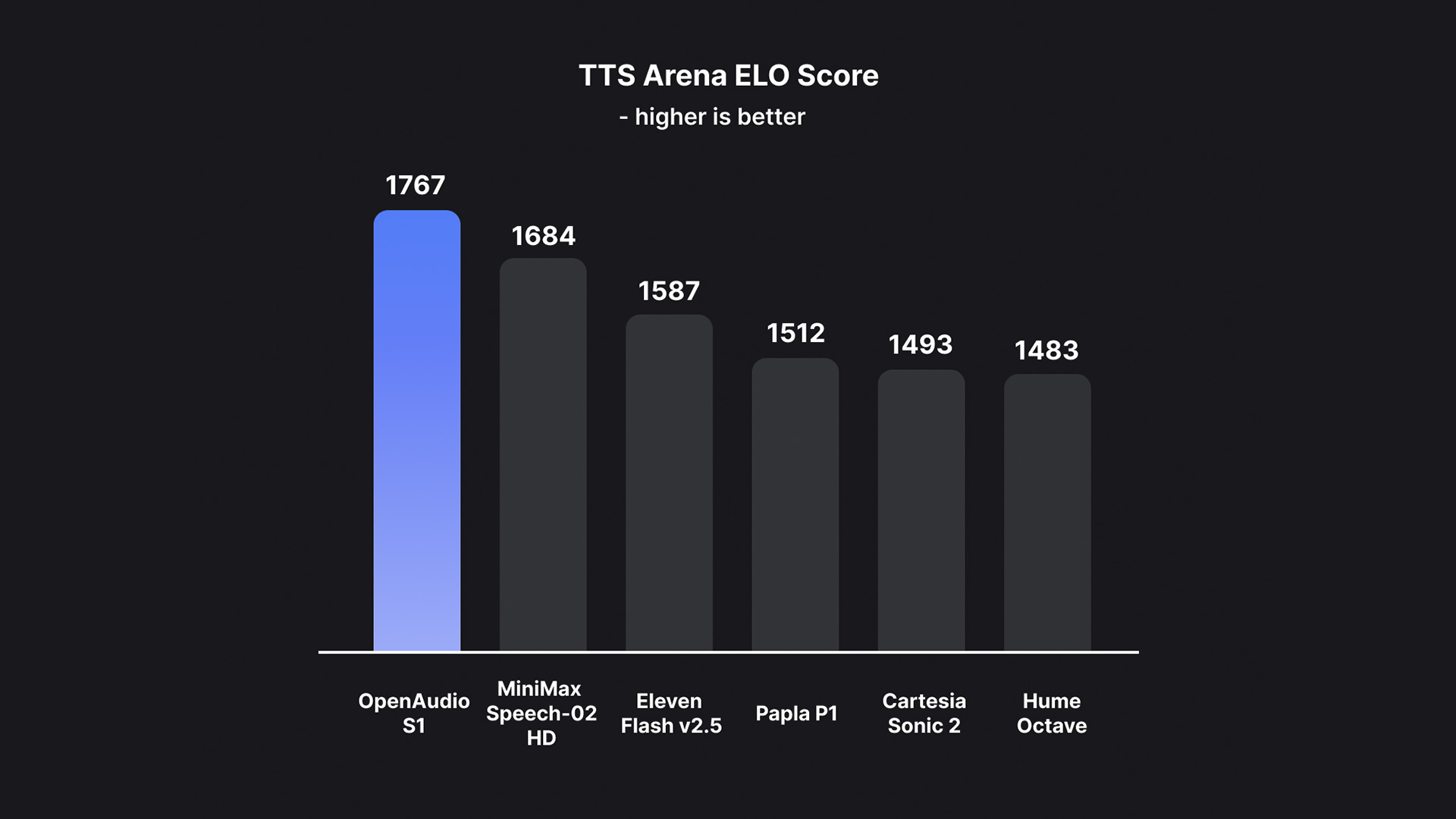
** Multiple indicators lead the world: **

-
Hugging Face TTS-Arena-V2 ranking 1 (human subjective rating)
-
Word Error Rate: 0.008, far better than industry models
-
Character Error Rate (word error rate): 0.004
-
A very low level of pseudo-verbals, miswords, misrepresentations, common TTS problems.
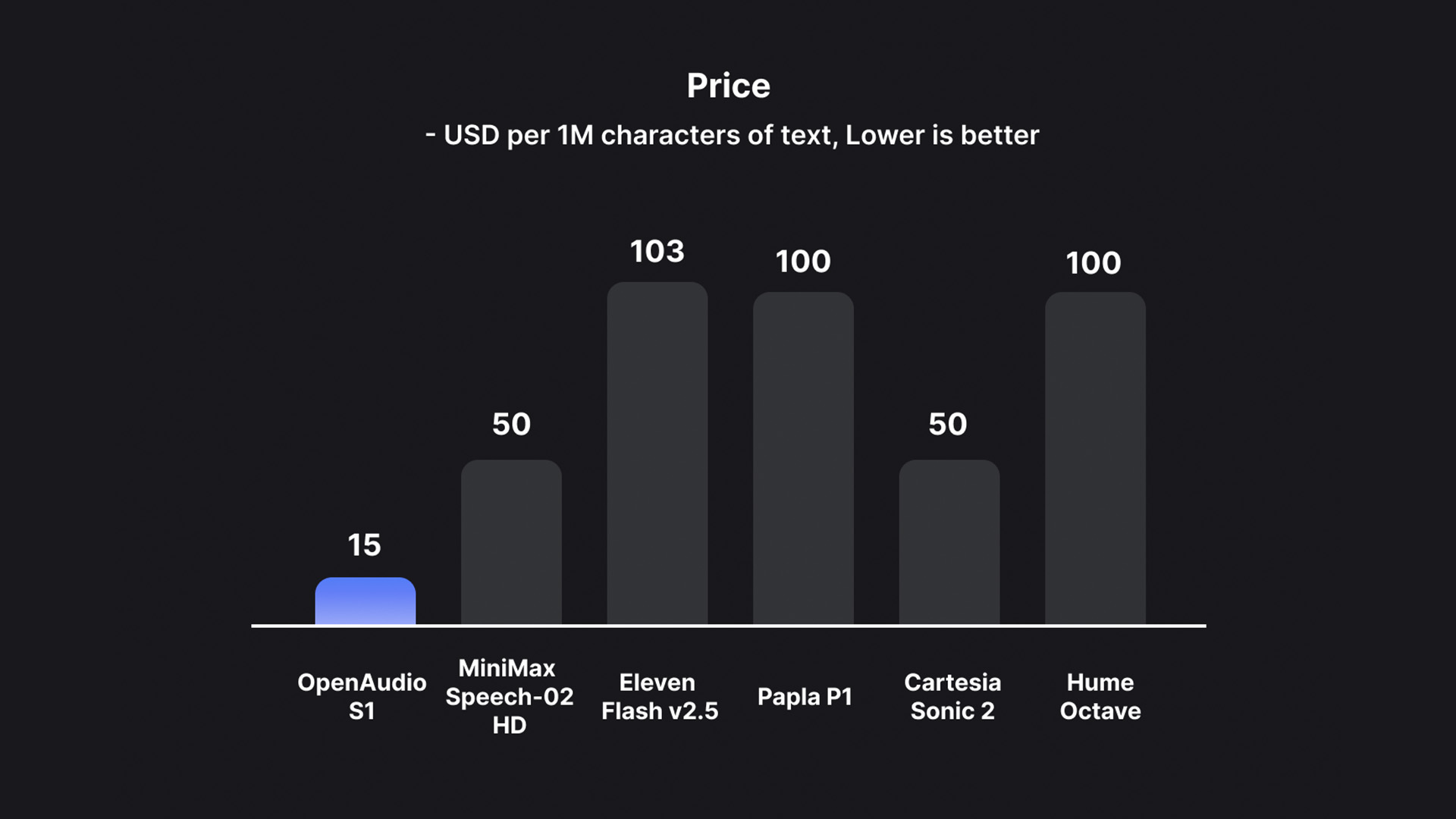
The price is very low, available to everyone
S1 is the most high-quality TTS model in the current market:
-
$15/million bytes only
-
Corresponds to approximately $0.8 hours audio costs
-
significantly below the market mainstream (e.g. ElevenLabs, PlayHT, etc.)
How do you experience it?
You can experience the voice effects of the model online through OpenAudio’s voice platform Fish Audio Playgroup (TTS currently available only, future support for TT, TextQA, AudioQA, etc.). https://openaudio.com Experience on Fish Audio Playgroup