- Core technology: audio-driven emoticon generation engine**
- # ** The process is extremely simple**
- # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # you know, you know, you know, # # # you know, you know, you know, you know,
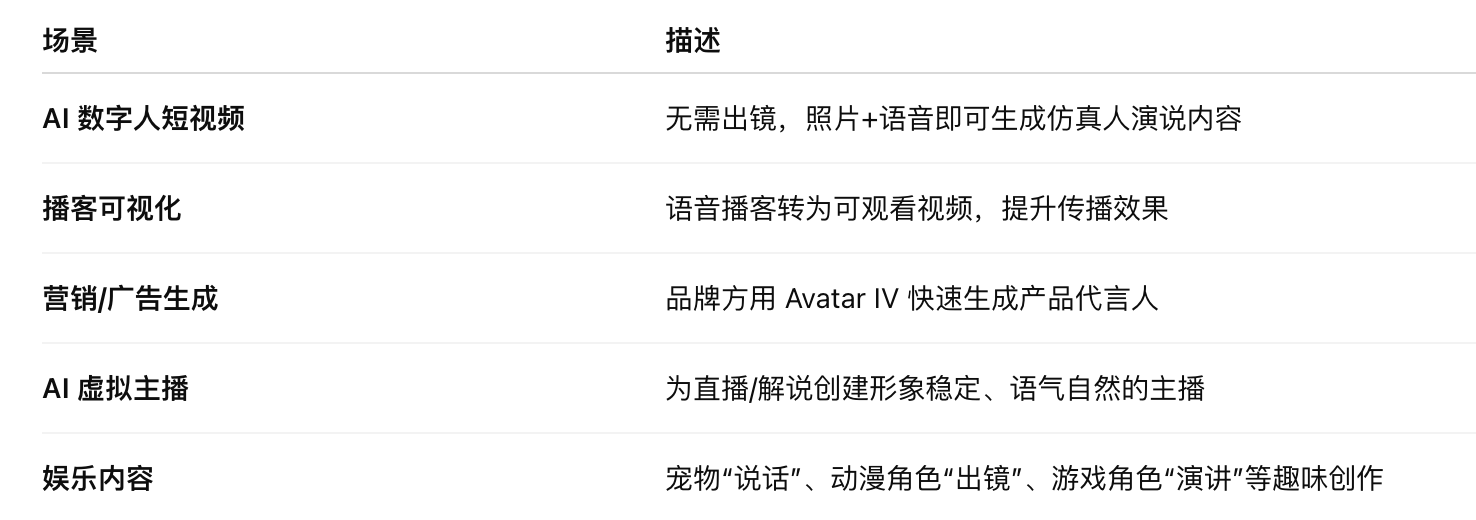
- Use scenes
HeyGen publishes its state-of-the-art AI model Avatar IV. A user can generate a personalized video by providing a photograph, a script and his own voice.
-
The new model is based on a “dispersive audio-driven emoticon engine” capable of synthesizing real facial expressions and movements according to the rhythm of speech, tone, emotion.
-
Support side-face images and angles change to produce more film-sensitive images.
-
Support for portraits, semi-body and body formats, adapted to different scenarios
-
Not only are voices synchronized, but they can also “understand” semantics and emotions, displaying micro-actions such as pauses, nods, tone swings, etc.
-
A variety of scenes can be used for virtual person videos, AI face-to-face content creation, manipulator effects, pet image drawing, play-playing and podcast visualization.
Core technology: audio-driven emoticon generation engine**
-
Diffusion-inspired Audio-to-Expression Engineering is no longer the traditional “synchronous voice-to-mouth” but analyses sound from deep neural networks: Tone
-
Rhythm
-
** Emotion**
-
Intent
And then driving facial expressions, head micro-motions and “Temporal Realism”:
-
Noding, pauses, eyebrows, changes in the mouth, and so on.
-
Showing a sense of speaking, not a simple reading.
# ** The process is extremely simple**
A self-photo, a text script, uploading your own voice. A video that is “as if I were talking to you” can be synthesized.
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # you know, you know, you know, # # # you know, you know, you know, you know,
♪ The real feeling is strong ♪
-
Faces flow naturally, not hard, not mechanical.
-
To achieve the “Video Simulation of Humans” quality
** Support multi-angle photos**
-
It’s not just the face, it’s the side, it’s the two-thirds angle.
-
Make the results more filmic.
According to AI to generate images
-
Support the movement of the human face created by Stable Diffusion or other tools
-
Voice-driven emoticons, consistent tone, synchronized rhythm.
** Increased creativity and personal expression**
-
Can make virtual characters ** sing ** (sync)
-
** Easy to create UGC ** Use only self-photographs and sound to make influential videos - no need to film.
-
Can give ** pet image** or ** illustration role** expression
-
Can give immotive or pixel characters the ability to broadcast orally.
-
** Dynamic comics and animations can be: ** Translating static animations or illustrations of cartoon style into dynamic, expressive videos - including emotions.
-
**Vision podcast content: ** To upgrade your audio content with every nuanced incarnation that can not only speak but also visually express the narrative.