- I, the personalized assistant who built you better
- II, Gemini Live: Visual + voice, problem solving on site**
- III, Deep Research: A stronger document analysis tool
- IV, Canvas Content Generation: Chat Record Seconds Page/Shower/ Test
- Five, Gemini for Chrome: AI partner in browser**
- Six, Imagen 4: Image generation further**
- VII, Veo 3: Toward film-grade video generation
- viii. New subscription system: Google AI Pro and Ultra
- Gemini is becoming an “AI operating system”
- Other updates
- Google Meet Add Real Time AI Simultaneous Translator
- Flow: AI driven movie studios are empty
- Google virtual dress trial tool
- Google releases Gemini Diffusion’s model based on proliferation mechanisms
- Other forewords: Agent Mode, Project Mariner, multi-end API call
- Android XR smart glasses first public presentation
At the 2025 Google I/O conference, Google presented a series of major upgrades to the AI assistant product under the flag Gemini. The update covers a number of core scenes such as search interactions, visual recognition, content generation, office integration, information processing, image and video creation, and provides a comprehensive picture of Gemini’s evolution from chat robots to multi-model AI platforms. Google has a very clear goal — to create Gemini as “** the most personal, proactive and powerful AI assistant**”.
I, the personalized assistant who built you better
Gemini formally introduces a deeper level of personal context capability. In addition to the search history association functionality that already exists, future users will be able to integrate information from Google applications such as Gmail, Google Drive, calendar, and Keep to provide Gemini with a “everything about you” context and further enhance the personalization and relevance of responses, subject to the availability of permission. This marks the evolution of Gemini from a passive response system to an AI partner with a “continuing perception of your life.”
II, Gemini Live: Visual + voice, problem solving on site**
In the real world, we often want to “point things to AI”, which is now a reality. Gemini Live has a powerful visual and screen-sharing feature, which users can share directly through cameras or screens, allowing AI to help identify problems and provide programs. This feature has been open to Android and iOS users since May 20 and will be gradually extended. In addition, Gemini Live is about to connect to Google calendars, Keep, tasks, maps, etc. For example, users can direct to the campaign poster, saying, “Add to my calendar,” and Gemini automatically interprets the information and completes the addition.
III, Deep Research: A stronger document analysis tool
Gemini also has an important update in his research and analysis function:
-
** Supports file and photo upload**: Users can drag PDFs, images, Word documents, etc. into the dialogue, and Gemini can understand, summarize and compare content.
-
**Integration Gmail and Google Drive (on-line): ** Allow Gemini, under user authorization, to extract relevant data from mail and cloud hard disks for multiple document matching and intelligent answers.
This significantly enhanced Gemini’s “information aggregation and analysis capacity” in the office landscape.
IV, Canvas Content Generation: Chat Record Seconds Page/Shower/ Test
Canvas, a multi-model creative tool for Gemini, is now undergoing a major upgrading:
-
Add a new “Create “ button to automatically generate interactive content based on the content of the current dialogue, without the need for the user to enter any more hint words.
-
Supports one key to convert the output of Deep Research into various forms of pages, podcast audio, interactive testing.
-
Fit for marketing, education, self-media, etc., to save every step of the creative process.
It’s not just AI’s auxiliary writing, it’s AI’s initiative to plan and publish.
Five, Gemini for Chrome: AI partner in browser**
Google integrated Gemini depth into Chrome browser with “Browsing Assistant” feature:
-
Users can click the Gemini icon on any page, enter or voice questions.
-
Capable of ** web summaries, terminology interpretation, cross-page questions and answers** without the need to switch tabs.
-
Reduce page jumps, ** good-bye tab hell**
-
It will initially be launched in the United States region ‘ s desktop version of Gemini subscriptions.
This is the Google-driven “ borderless assistant” strategy, in which AI should be seamlessly embedded and responsive in any software interface.
Six, Imagen 4: Image generation further**
In the area of image generation, Google has launched an upgraded model Imagen 4, which brings with it:
-
Clearer and more nuanced image details.
-
More natural colours.
-
More reliable text and label generation
-
The visual performance of people ‘ s faces, clothing textures, background drawings, etc. have reached new heights.
Imogen 4 is now open for free use by all Gemini users and allows for high-quality image creation without subscription.




VII, Veo 3: Toward film-grade video generation
In addition to the images, Google has released a completely new video-generation model Veo 3:
-
Support the generation of high-resolution video (up to 4K resolution)
-
Could add ** audio, background noise, white lines**
-
Understanding more complex narrative logic and dynamics
Veo 3 means that Gemini is no longer just a graphic assistant, but is also becoming “director of the image creator AI”.
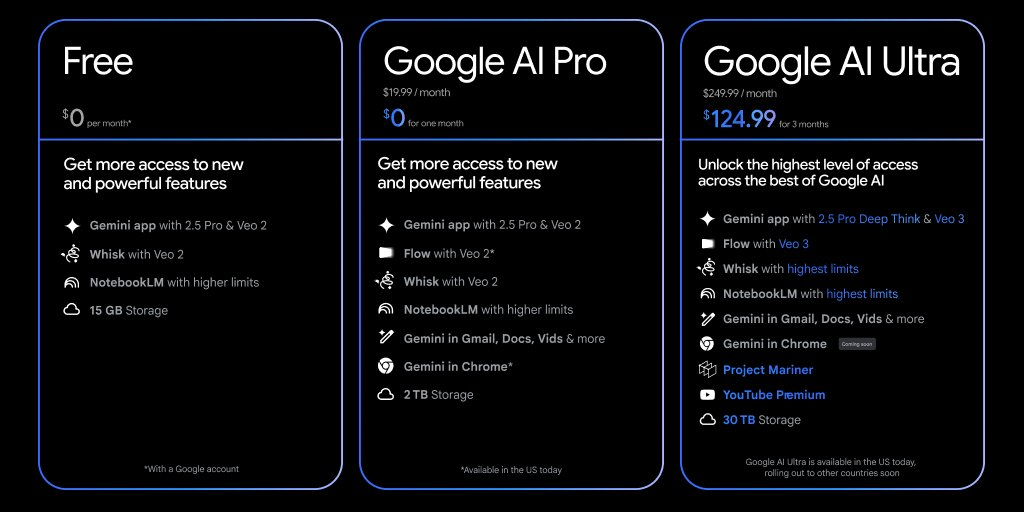
viii. New subscription system: Google AI Pro and Ultra
To meet the deep usage needs of different users, Google has introduced a new AI subscription level:
-
Google AI Pro: For day-to-day step users
-
Google AI Ultra: Created for high-ranking creators and professionals to provide: Higher frequency of use and context length
-
Faster response speed.
-
Testing of state-of-the-art models such as Veo 3, Imagen 4 in advance
Ultra clearly shows the ambition of Google at the high end of the AI market against the pro-paying user of ChatGPT of OpenAI.
Gemini is becoming an “AI operating system”
This Google Gemini upgrade is no longer limited to talking questions and answers or web helpers, but is moving towards a comprehensive integration of vision, language, content, tools, behavioral “AI at work”. Gemini not only “to answer questions”, but also “to deal with tasks”, “to integrate context”, “to produce results”, “to make recommendations” may become “AI executives” in personal work streams in the future. Google is pushing the AI product to the ground at an amazing speed and breadth, and Gemini’s every turn is an early preview of “the future of office.”
Other updates
Google Meet Add Real Time AI Simultaneous Translator
Google Meet introduces an AI voice translation that initially supports dialogue between English and Spanish. Most important:
-
Retain the original voice, tone and tone of the user and not change the style of the language
-
Auto-synchronization of the content of a movie like that.
This is a key development for AI in the area of voice, not just in terms of comprehension, but in terms of “** real-time translation + simulating synthesis**” close to the real AI simultaneous translator. Cross-linguistic meetings have become seamless and greatly expand the capacity for remote collaboration.
Flow: AI driven movie studios are empty
Google has launched a new creative platform:
-
seamless integration of Veo, Imagen, Gemini.
-
Keeping the image, style, background consistent in different lenses
-
Independent creators can produce a full film (including animation, dialogue, style) on their own
This is not just video generation; it is a complete “AI narrative platform” equivalent to the Midjourney + ChatGPT + Runway + Premiere integration. AI allows video content to be created into an individual-scaled phase.
Google virtual dress trial tool
A.I. will generate an actual picture of you wearing the merchandise in a few seconds.
-
Based on a new generation of image-generation models, designed for fashion scenes.
-
Provision of real-time credible commodity information based on global commodity data of 50 billion
-
Multiple-conditional search and comparison, price analysis, depending on the user ‘ s needs.
-
The shopping process is fully automated, and the bill can be paid automatically.
Details: Google Launches a virtual dress-on-the-job tool to upload a picture of your own for a few seconds to generate an accurate picture of the effects of your wearing the commodity and to automatically place a single XiaoHu.AI Academy at the 2025 Google I/O Congress, Google announced a very attractive consumer level AI application: Virtual Try-On. Based on a new generation image-generation model, dedicated to fashion scenes https://www.xiaohu.ai/c/xiaohu-ai/google-ai-7ff104![7] (https://assets-v2.circle.so/ff8oxh6mbz5pwvexq5xqwrad7]
Google releases Gemini Diffusion’s model based on proliferation mechanisms
The speed of 2,000 token/seconds is comparable to that of Gemini 2.0 Flash-Lite from the traditional word-by-word generation to “one generation, step-by-step” Gemini Diffusion, which is particularly good at code generation and can almost write high-quality codes in real time, with a code speed of 2,000 tokens/sec. Gemini Diffusion works: first add a “complete text expression” to noise damage, then the training model is gradually “noise-by-noise” and then reverts to a reasonable text. ** Strengths: - Allows holistic generation: a broad draft can be generated from the beginning and then repeated; - Natural support for error correction and editing: because each step is essentially “adapted”; - Fits for complex structure generation: for example, mathematics, programming language, requires structure and semantic rigour. Details: Google releases Gemini Diffusion’s proliferation-based model at a speed of 2000 token/seconds comparable to Gemini 2.0. Flash-Lite XiaoHu.AI Institute at Google I/O 2025 made public for the first time the cutting-edge technology it was developing - Gemini Diffusion, an entirely new method of applying the diffusion model to language modelling. What is … https://www.xiaohu.ai/c/xiaohu-ai/google-gemini-diffusion-2000-token-gemini-2-0-flash-lite![8] (https://assets-v2.circle.so/s32ky1h1h7kkkkgg9lmkluudq) #NotebookLM Launch Video Summary At the 2025 Google I/O Congress, the Notebook AI Assistant Platform under the Google flag **NotebookLM announced a surprising new feature - Video Overviews (video summary). Through this feature, users will automatically generate short video summaries from various content sources (e.g. PDF, pictures, documents, etc.). While only English is currently supported, this update will undoubtedly upgrade NotebookLM from a text-based knowledge collation tool to an AI learning platform that supports “multimodel content generation “ . ** Generate video from any upload** Whether PDF reports, notebooks, web content and scripts, NotebookLM will support the production of videos based on these materials. This means:
- The academic thesis generates a Coptic video.
PDF can be converted into a video presentation.
- Picture Note Visual Output
** Generates a short video summary** The emphasis is on “overview”, which is a quick overview:
-
Short video (possibly within 1-2 minutes)
-
Content extraction, suitable for fast-paced learning, content redisk, social media sharing
Other forewords: Agent Mode, Project Mariner, multi-end API call
-
Agent Mode: Gemini will be able to carry out tasks such as filling out forms, processing web content, etc.
-
Project Mariner Multitask AI Module (priority for Ultra subscribers in the United States region)
-
Gemini API supports desktop call, i.e. AI can operate computer software, files, commands, etc.
These are the prototypes for building “AI uses computers “ , which are equivalent to an automated combination of GPT-4 + AutoGPT + computer scripts. Voice from chat AI Operational smart agent.
Android XR smart glasses first public presentation
Google shows the prototype Android XR smart glasses:
-
Real-time translation, navigation, mission alert.
-
Integration with Gemini, real visual assistant.
-
Apple-like Vision Pro, but closer to everyday life and practical scenes.
This marks Google moving towards the “AI+ Hardware+Operational System” integration platform. Gemini will become the intelligent layer of the real world and is no longer confined to the screen.