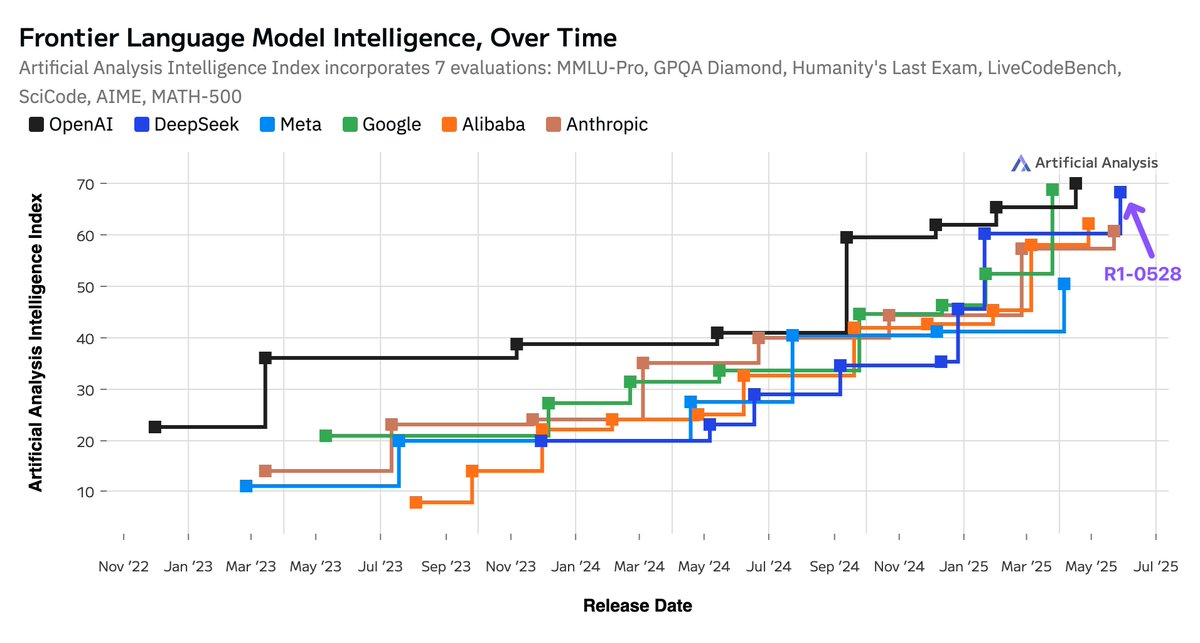
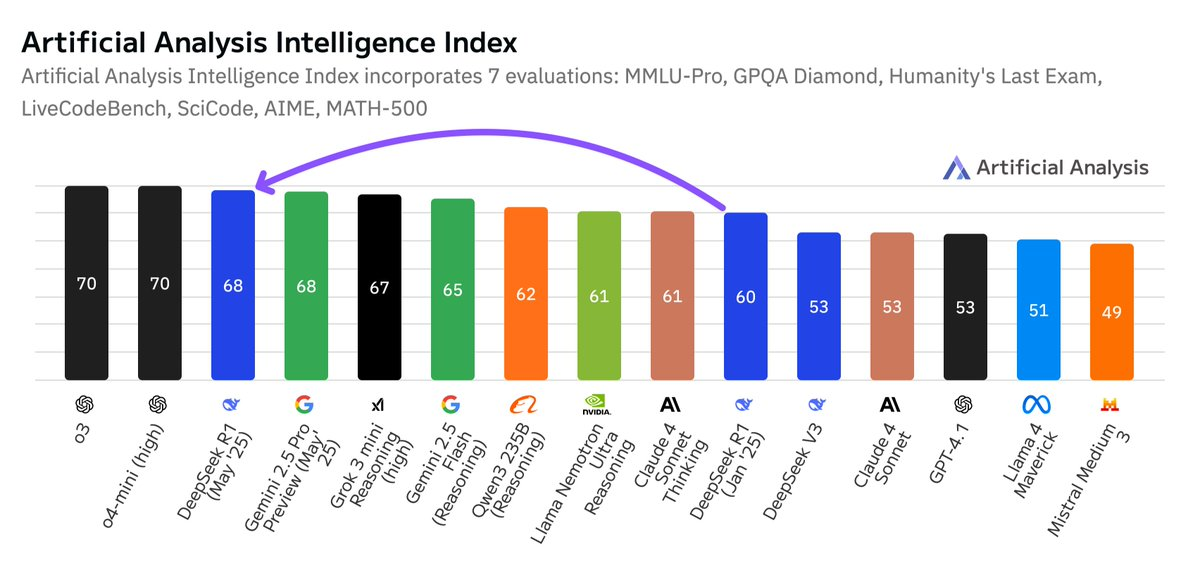
@ArtificialAnlys published an article calling DeepSeek’s recently released model R1-0528 post-training update, significantly increasing the model’s performance in multiple smart assessments, up to 68 points, with Google Gemini 2.5 Pro as the second-largest in the world, after the OpenAI series. He was among the second largest artificial intelligence laboratories in the world. The update did not replace the architecture, but rather enabled it to make significant progress on a number of capacity indicators, such as mathematics, code generation, and scientific reasoning. The increase in token usage also showed a more detailed and comprehensive response. In the global AI pattern, this marks the opening-source model’s level of intelligence close to the top closed-source model. More importantly, DeepSeek from China is gradually narrowing the gap between the leading AI laboratories in the United States, and has already taken the lead in some areas. This trend suggests that even if computing resources are not as good as OpenAI, other AI laboratories have the opportunity to catch up and approach state-of-the-art intelligence performance through strategies such as intensive learning.
Here’s the translation of its contents
Artificial Analysis (@ArtificialAnlys) published on May 29:
DeepSeek’s R1 goes beyond xAI, Meta and Anthropic to become the world’s second largest AI laboratory with Google, while sitting on the top of the open-source weight model.
-
Comprehensive upgrading of intelligence: this is particularly evident in AIME 2024 (competing mathematics, +21 points), LiveCodeBench (code generation, +15 points), GPQA Diamond (science reasoning, +10 points), Humanity’s Last Exam (sense and knowledge, +6 points).
-
No change in structure: R1-0528 is a post-training update that does not change the V3/R1 architecture - still a super-large model with a total 671B parameter (37B active parameter).
-
Significant increase in programming capacity: R1 is now at the same level as Gemini 2.5 Pro in the manual analysis of programming indices and lags behind only o4-mini (high match) and o3.
-
A significant increase in the use of Token: R1-0528 used 99 million tokens in the assessment, 40 per cent more than the original R1 71 million. That is, the new version, “Thougher Thinking.” This is still not the highest, but the number of tokens used by Gemini 2.5 Pro is 30 per cent more than R1-0528.
** Some conclusions on AI:**
-
The gap between open-source and closed-source models has narrowed unprecedentedly: open-source weight models can still maintain smart growth comparable to proprietary models. DeepSeek R1 has returned to the same position since January, when he first took the second largest position in the world.
-
The Chinese-American technological axiom: The model of the AI lab in China has almost evened the American counterpart. This release continues this trend again. DeepSeek is now leading the AI smartness index of Anthropic and Meta.
-
Strengthening learning for intellectual advancement: DeepSeek has demonstrated the critical role of RL in the reasoning model through training (especially intensive learning) without changing its structure and pre-training. OpenAI has expanded the RL by 10 times between o1 and o3, while DeepSeek has demonstrated its ability to keep up with this rhythm. The expansion of RL requires fewer computing resources, more efficient and more conducive to an AI laboratory with limited resources than pre-training.
Detailed report: https://artificialanalysis.ai/models/deepseek-r1/providers