- Core competencies
- 1 Precision image understanding and content re-engineering
- # 3 Multilingual support, cross-linguistic accessibility
- Presentation and ability
- # Image generation and creation
- # # multi-step, complex command response
- Feel and understand the mission
- Key upgrades compared to the old version (VL Plus/ VL Max)
Qwen V Lo is a unified multimodel large model (Unified Multimodular Model) capable of understanding images while generating and editing them and of controlling the process flexibly through natural language instructions. Not only can it “see” the image content, but it can also be finely modified or completely new in the light of understanding, resulting in a closed circle from visual perception to visual creation. It is currently a preview version that can be used through Qwen Chat.
Core competencies
1 Precision image understanding and content re-engineering
-
Accurate identification of ** type of object, structural characteristics, style** in the image.
-
To retain the main structure of the original map and avoid “deformation” or “false” when the image is modified (e.g. changing colour, style migration).
Examples: Users uploaded a picture of the car, saying, “Change the colour to blue.” Traditional models may have changed the contour or failed brand recognition; Qwen V Lo not only recognizes the model, but also retains the body structure, only naturally changing the color.
##2 Image edit under open language control Qwen VLo supports the free expression of creative intent in natural languages, such as:
-
“Change this picture to the 19th century painting style.”
-
“Let the sky be clear.”
-
“Let the person’s background turn into the city’s night vision.”
These orders do not require a fixed format, the model can be understood in a flexible manner and the modifications can be finalized with precision. It may also perform a combination operation, such as:
-
Modify the background + style + add object;
-
Achieving a variety of uses, such as image style migration, site re-engineering and illustration details.
# 3 Multilingual support, cross-linguistic accessibility
Qwen V Lo supports multi-language command input ** Chinese, English**, etc. Users can interact directly with the system in their mother tongue and greatly improve their use experience.
#4 Support for perception-type tasks (Visual understanding of tasks)
Not only can you generate images, Qwen V Lo can also handle traditional CV (computer visual) tasks:

-
easier control of detail and overall consistency;
-
Supporting long maps, complex layouts;
-
Closer to the logic of human drawings.
Simple comprehension: it is ** “understanding drawing”** and not “all generation and repair”.
Presentation and ability
# Image generation and creation
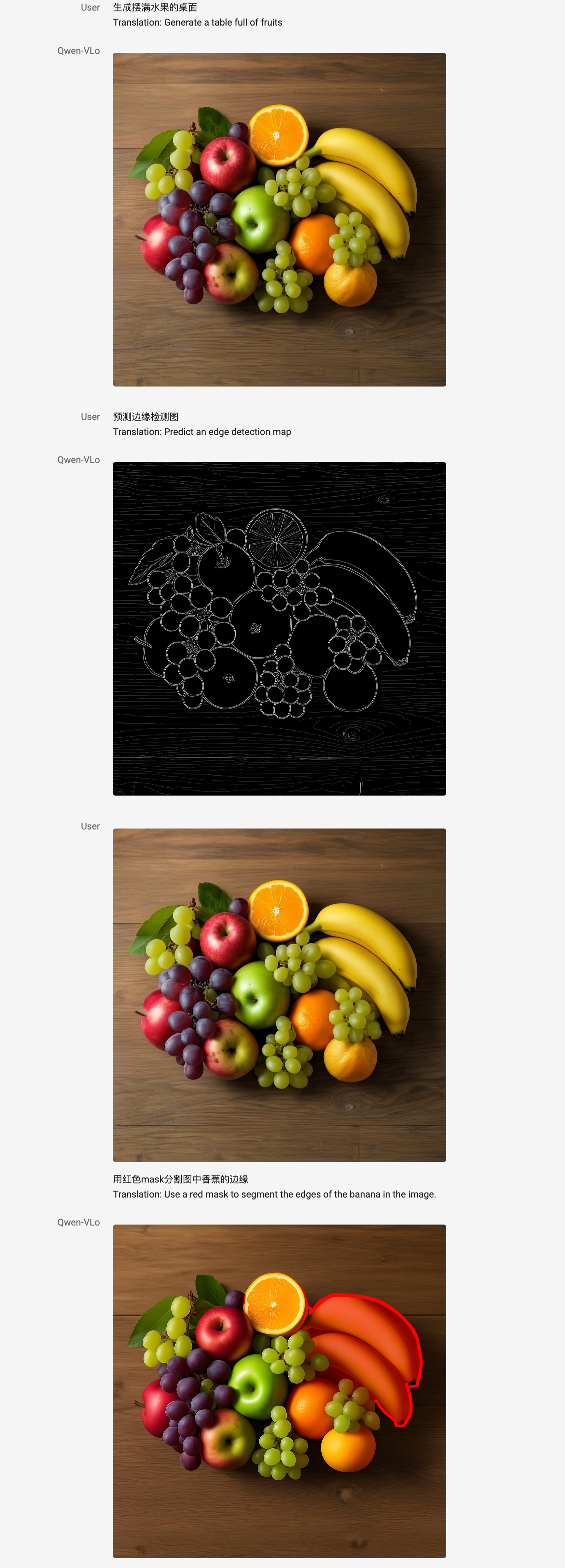
Qwen V Lo can directly generate images and modify them, for example, by replacing background, adding subjects, moving style, and even completing large changes based on open instructions, including visual perception tasks such as detection and partitioning.
-
Supports the input of pure text (e.g., “Draw a lovely wooddog”) to generate images
-
Support the uploading of pictures and modification (e.g. “Put it on a hat”) - edit images
-
Use of ** step-by-step generation mechanism** (left to right, top to bottom) to increase detail stability
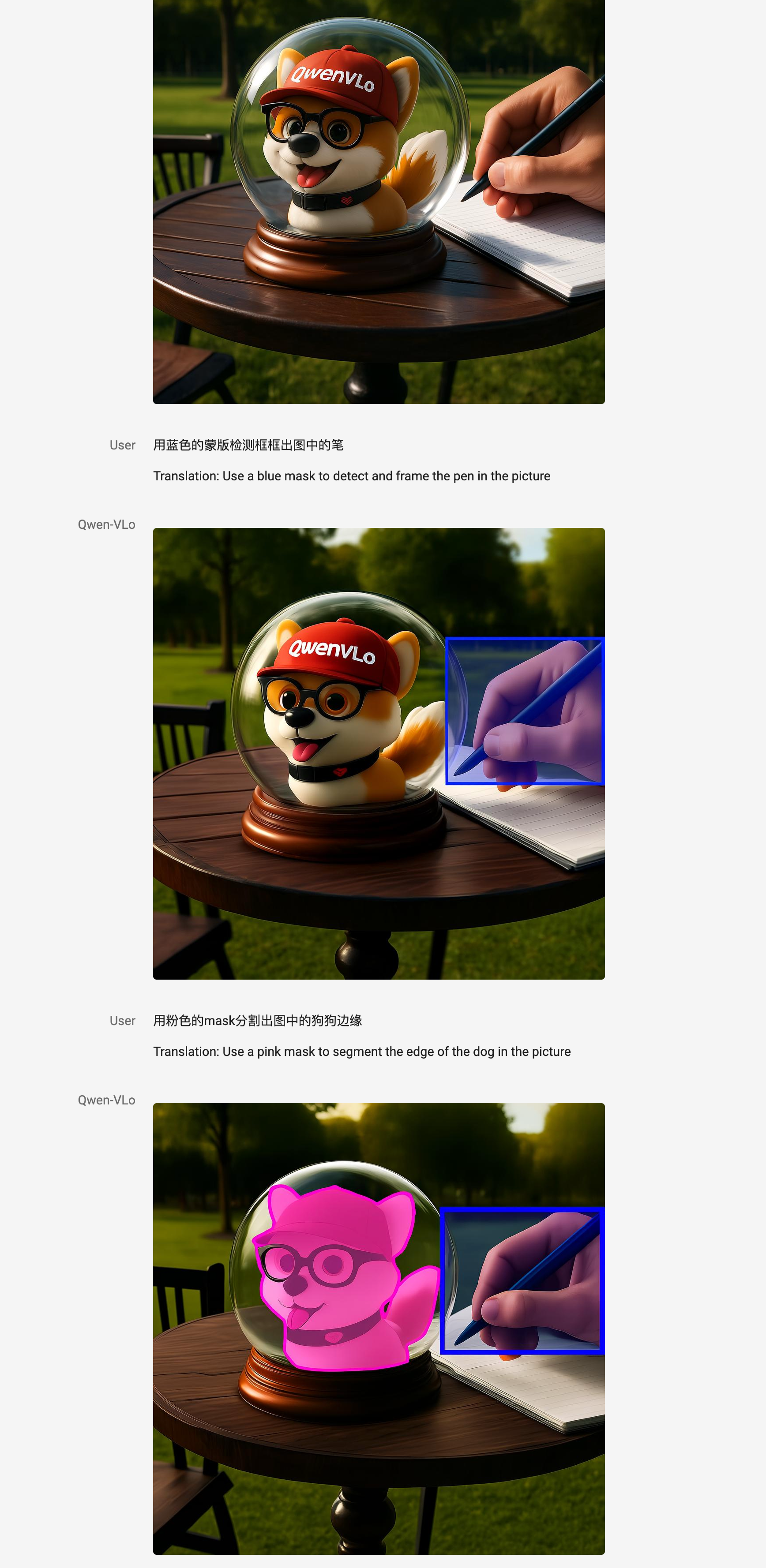
# # multi-step, complex command response
- Support multi-operational combinations, such as “Creating retrogent style, changing background, adding text”, once completed.
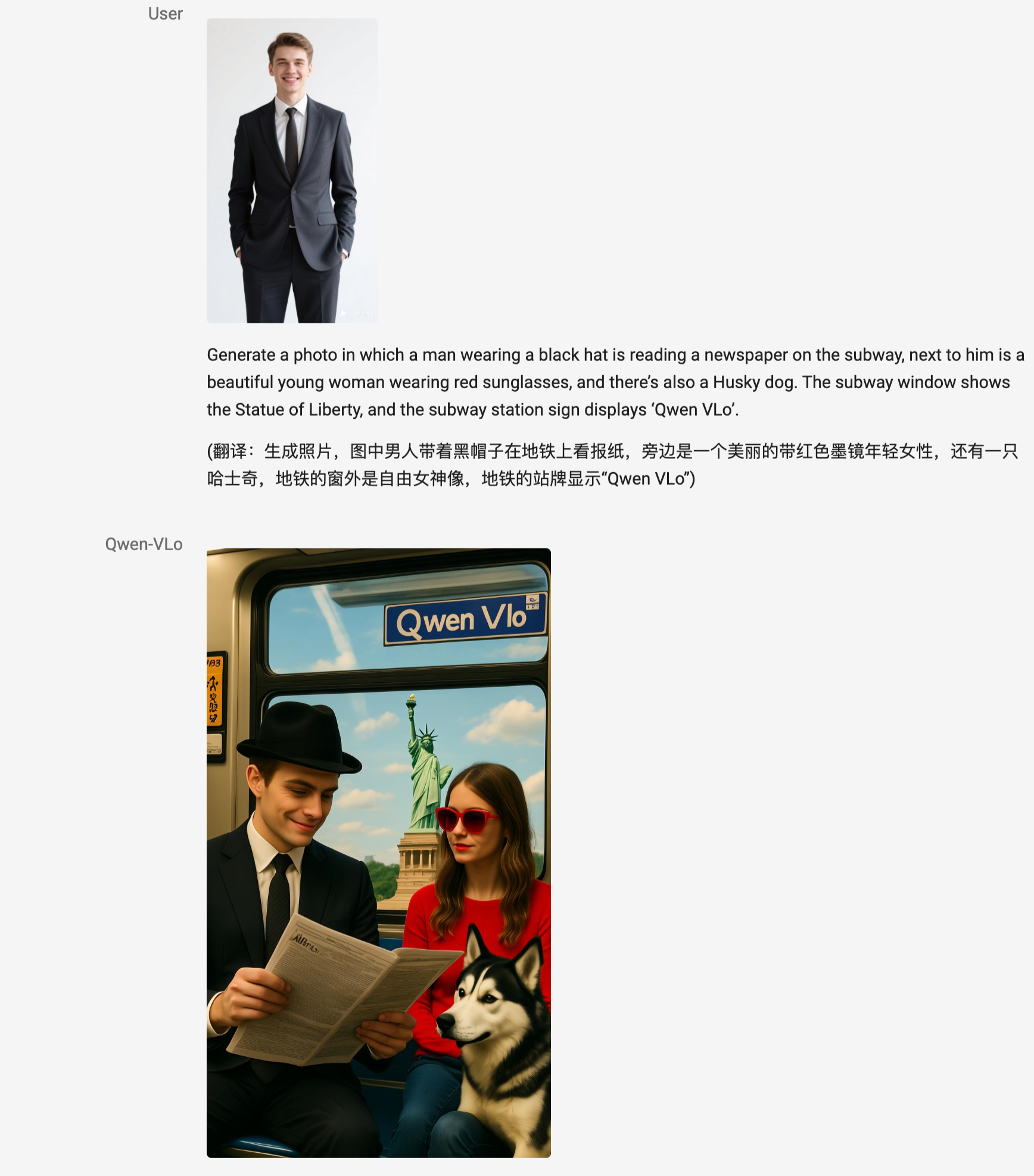
Feel and understand the mission
- An intermediate visual perception result, such as detection frames, partition maps, edge maps, etc., can be generated;
- Supports input understanding and generation of multiple images. (The multi-figure input function is not officially online. Please look forward to it.

Key upgrades compared to the old version (VL Plus/ VL Max)
