- Words and dialects support the details
- Technical principles and data base
- How to use: API and code access
- Model=model
- Check if excuse.output is None
- Check if excuse.output.audio exists
The core capability is to convert the text entered into Chinese and English into a voice output with natural expression. Compared to the traditional TTS model, the biggest bright spots for Qwen-TTS are:
-
** High Nature**: Voice expression is closer to the person, with emotion, rhythm, tone change;
-
** Multilingual and dialectic support**: currently in favour of Mandarin, English and three Chinese dialects (Beijing, Shanghai, Sichuan);
-
** Multisound selection**: Provides different genders, tone and accents, adapted to diverse scenes.
Words and dialects support the details
Supported speech variant:

Technical principles and data base
- Large-scale training materials support The model training used 3 million hours of voice data, including Chinese and English alignment data, as well as a wealth of dialectic material, which enabled the model not only to be natural in voice but also to imitate the language style of different regions.
- Rhythm and Emotional Modelling Qwen-TTS supports ** automatic adaptation of text speed, accent, rhythm and emotional performance**. For example, when expressing surprise, tenderness or anger, the voice automatically reflects the corresponding emotion, without the need for an overt sign.
- Sound modelling and style migration
-
The model allows the same sentence to produce a voice output in a variety of styles (e.g. male/female, Northern/South).
-
Current support 7 sounds: Cherry, Ethan, Chelisie, Serena (Chinese and English)
-
Dylan, Jada, Sunny.
Performance assessment:
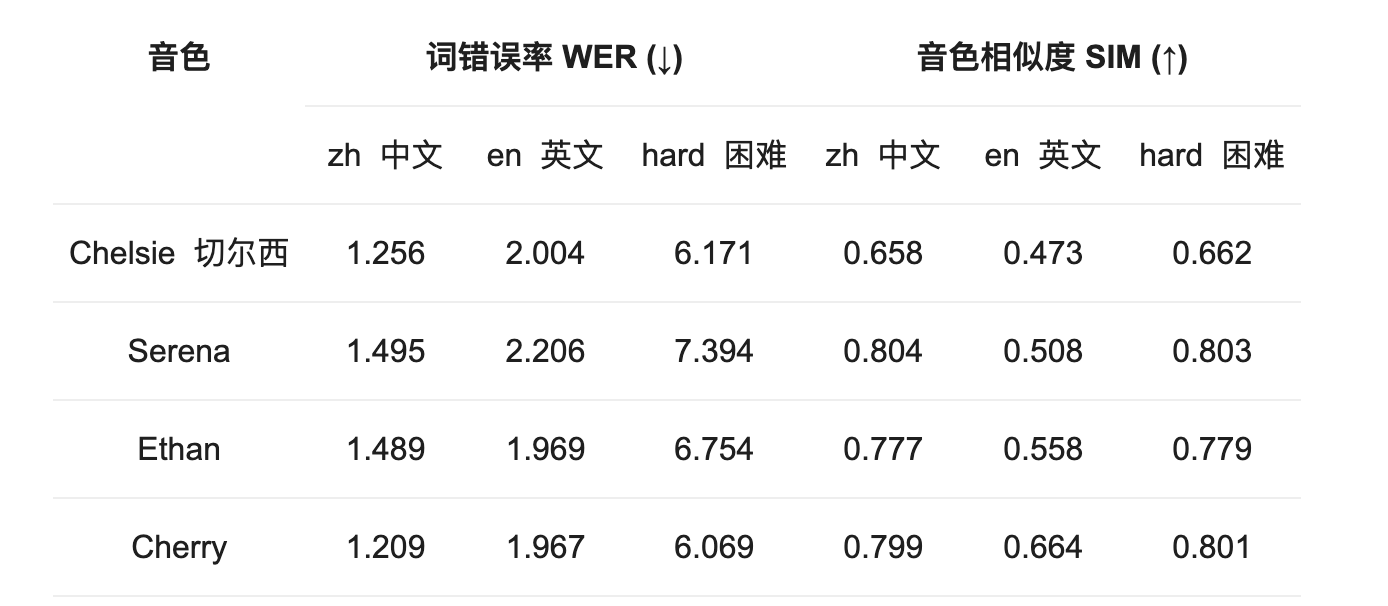
-
**WER (word error rate): ** The accuracy of speech recognition reverse text should be as low as possible;
-
SIM (symmetry of sound) measures the degree of proximity between the generation and the target sound, as high as possible.
How to use: API and code access
** Prices:**
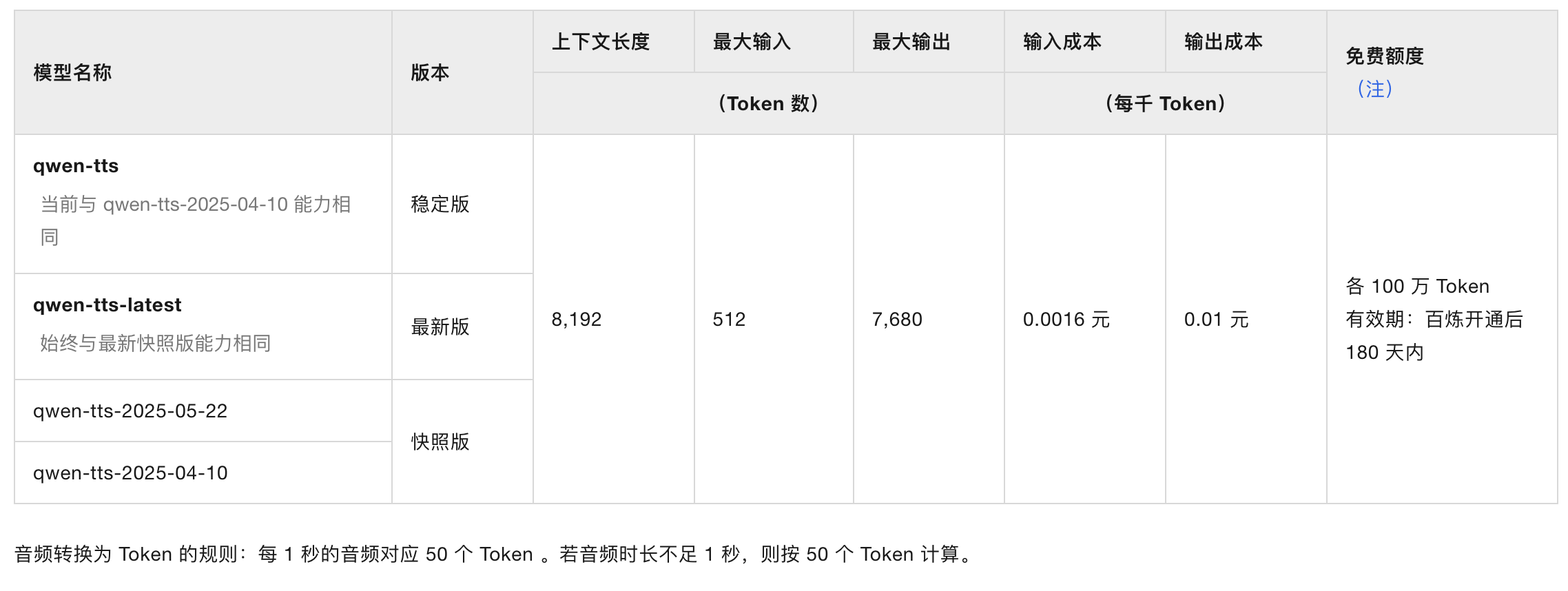
Model=model
I don’t know what you’re talking about, but I don’t know what you’re talking about. I don’t know what you’re talking about, but I don’t know what you’re talking about. It’s not like I’m going to have to go back to school. I’m not sure what I’m talking about. Check if excuse is None If excuse is None: “API called returned None response”
Check if excuse.output is None
If excuse.output is None: I’m sorry, RuntimeError (“API call failed: recall.output is None”)
Check if excuse.output.audio exists
If not hasattr (response.output, ‘audio’) or recall.output.audio is None: “API calls failed: recall.output.audio is None or missing” Audio_url = recall.output.audio [“url”] ♪ Turn audio_url ♪ Exception as e: “Speech synthesis failed: {e}) If you don’t like it, you’ll have to take care of it. Try: Resp = requests.get (audio_url, timeout=10) I don’t know what you’re talking about, resp.raise_for_status() With open (save_path, ‘wb’) as f: F.Write (resp.content) I’m sorry, but I’m sorry, I’m sorry, but I’m sorry, I’m sorry, but I’m sorry, I’m sorry, but I’m sorry, I’m sorry, but I’m sorry, I’m sorry, but I’m sorry, I’m sorry, but I’m sorry, I’m sorry, I’m sorry, I’m sorry, but I’m sorry, I’m sorry, I’m sorry, I’m sorry, I’m sorry, but I’m sorry, I’m sorry, I’m sorry, I’m sorry, I’m sorry, I’m sorry, I’m sorry, I’m sorry, but… Exception as e: “Download failed: {e}) Def main(): Text = ( Yo, guess what? I’m looking at the NBA today, and Curry’s pitching and playing, and I’m gonna have to call him “Father” in the basket. I’m not sure what I’m talking about. “downloaded_audio.wav” Try: Audio_url = synthesize_speech(text) I don’t know what you’re talking about, but I don’t know what you’re talking about. Exception as e: print(e) If name_ = “main”: Main()