- Core bright spot function (compatibility of performance, efficiency and privacy)
- # 1. Extremely light and quick response
- # 3. Full local operation, privacy priority
- Multi-module capacity has increased
- Model use: building the next generation of “accidental intelligence experience”
- How’s it going?
- Core technical detail
- How to use Gemma 3n?
- Detailed description:
Gemma 3n (“n” means Nano or Next-gen) is the latest lightweight open source AI model introduced by Google, which aims to achieve the three objectives of “on-device+ multi-model perception + low-efficiency delay”. It is the first preview of the model architecture optimized for mobile devices** after the Gemma 3 series (support to desktop/coated reasoning) and forms the technical basis for the next generation of the Gemini Nano series**.
-
Parameters size: 5B and 8B (5 billion and 8 billion parameters, respectively)
-
Support of patterns: text, images, audio (voice recognition and translation), video (to be opened)

Core bright spot function (compatibility of performance, efficiency and privacy)
# 1. Extremely light and quick response
- **The response speed is about 1.5 times higher ** (cf. Gemma 3 4B) to achieve a <500ms delay in the first word on the high end Android mobile phone.
Per-Layer Embeddings (PLE), which benefited from the innovation of Deepmind, the occupancy of memory has been significantly reduced; Although the model parameters are: 5B (5 billion) and 8B (8 billion);
The memory required at the time of actual operation is only:
-
~2GB (5B model)
-
~3GB (8B model)
This means that:** middle-end Android mobile phones can also run large model reasoning** without cloud support. Mobile hardware platforms such as Qualcomm, MediaTek, Samsung, etc.
2. Dynamic adjustable model structure (Mix’n’Match architecture)
“Mix’n’Match” structure allows the 5B model to automatically switch to an embedded 2B submodel;
-
The model structure embedded an embedded submodel (2B active memory model embedded in the 4B master model), which the developer can ** dynamic adjustment accuracy and reasoning speed** and adapt to different use scenarios;
-
A balance between accuracy and speed, depending on the capacity of the equipment or the user’s needs;
-
Such a structure would achieve “one model covering multiple scenarios”
-
Excellent performance in energy consumption and control, especially for battery-sensitive equipment (cell phones, glasses, headphones, peripherals).
# 3. Full local operation, privacy priority
-
The operation of the reasoned task without the need for networking;
-
All data are processed on the equipment, not on the cloud, and the privacy of users is guaranteed;
-
For mobile phones, notebooks, peripherals, etc.
Multi-module capacity has increased
Gemma 3n is one of the most advanced currently Google movable multimodule open source models and its range of support includes:

Model use: building the next generation of “accidental intelligence experience”
Expected application scenario

How’s it going?
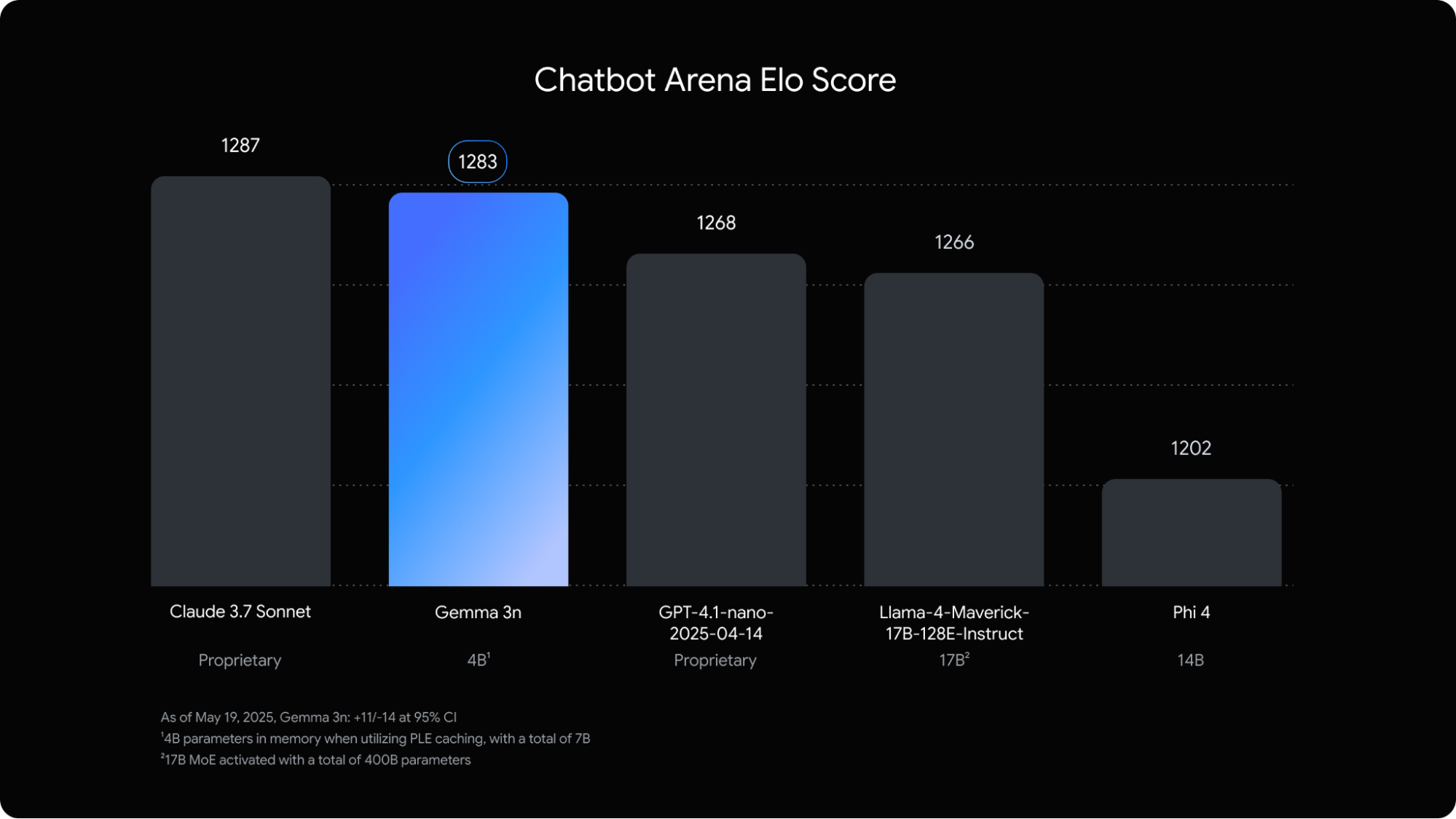
Natural language mission** Google describes its model as “high ahead” in Chatbot Arena’s ranking, and in the user preference rating:
-
Comparable to mainstream open source models such as Mistral 7B, Phi-3, LLama 3;
-
To demonstrate stability in the bilingual Chinese and English missions, particularly in dealing with the multi-round dialogue, the production of long texts, and the logical question-and-answer.
(a) Multilingual performance:
-
Scores in multilingual benchmark (e.g. WT24+, ChrF) 50.1%;
-
Special performance in the ** Japanese, German, Korean, French, Spanish** tasks;
-
This suggests that it is superior to many Western-led models in terms of the adaptability of international markets.

Core technical detail
One of the key technical bright spots for Gemma 3n is ** a significant reduction in memory occupancy while running**, which is achieved in three ways:
#1 Per-Layer Embedding (PLE)
-
** What**: a new embedded strategy proposed by Google Deepmind;
-
** Activation**: Each layer uses an independent low-dimensional embedding vector instead of a full model sharing of embedding tables;
-
** Strength**: Reduction of memory replication;
-
Better compression of the expression space;
-
Support for loading on demand (lazy load);
Efficacy: Reduce the dynamic running memory of the 5B/ 8B parameter model to approximately 2GB/ 3GB;
- Runs a lightweight version similar to a 2B or 4B “ disguise “ of the large model.
#2Key-Value Cache Sharing (KVC Sharing)
-
** What**: Transformer models need to store intermediate results of attention mechanisms in their reasoning (Key and Value);
-
** Activation**: multiple layers or steps to share this cache, reducing double counting and memory redundancy;
-
** Strength**: (b) Reducing the cost of reasoning memory;
-
Speed up sequence generation and increase multiple rounds of interactive experience.
#3 Advanced Activation Quality (AAQ)
-
** What**: Quantify intermediate activation values (e.g. from float32 to int8 or infourth);
-
** Activation**: Significant reduction of model computing and memory bandwidth requirements;
-
** Strength**: (a) Maintaining model accuracy while reducing size;
-
Supporting the efficient operation of models on mobile chips (Qualcomm, MediaTek);
-
In conjunction with PLE, KVC, further compressed to acceptable levels of mobile equipment.
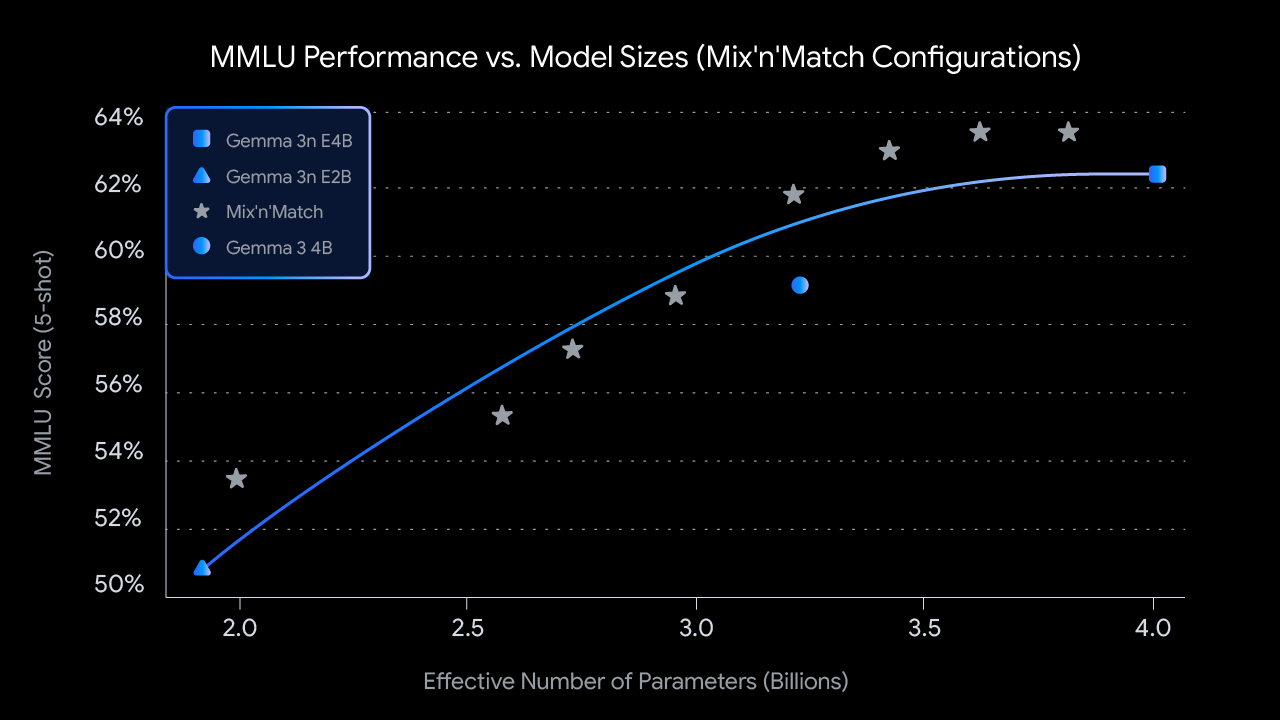
Mixed architecture design: Mix ‘n ‘match mechanism
** “A set of models, multiple capabilities”** Gemma 3n has achieved an embedded model mechanism internally through MatFormer training strategy: The model structure function indicates that the main model (e.g. 4B) has a high-precision reasoning sub-model (e.g. 2B) performance light, that the response to rapid dynamic switching is based on mission complexity, that the equipment resource automatically selects the operational path sub-model successor sub-model weights are shared by the main model, and that duplication of deployments is avoided This structure has the following advantages:
-
Developers do not need to deploy multiple model versions;
-
The trade-off between dynamic reconciliation quality and delay at running (e.g. navigational assistant vs semantic translation);
-
Improve energy consumption control capabilities and adapt to high-end low-end equipment.
How to use Gemma 3n?
Google has opened up two ways for different groups of people: Mode I: AI Studio (web version)
-
Without installation, to experience text interpretation and generation of the model directly in the browser;
-
Fit for product managers, developers to preview model effects.
Address: Google AI Studio (Google account required) Mode II: Google AI Edge** (local development tool)**
-
Fit for developers to integrate models into APPs, local systems, hardware equipment;
-
Provide SDK, documents, code examples to support the deployment of text and image models;
-
Support for Android, Chrome, embedded equipment, etc.
Detailed description:
Official presentation: https://developments.googleblog.com/en/introduction-gemma-3n/