- What’s the core of it?
- 1. Transparent Proxy
- The way you’re actually using it
- Performance and cost – practical and not expensive
- # # # # # # # # performance advantage
- # # price model
- What if something goes wrong?
- Support scope and compatibility
- To sum up:
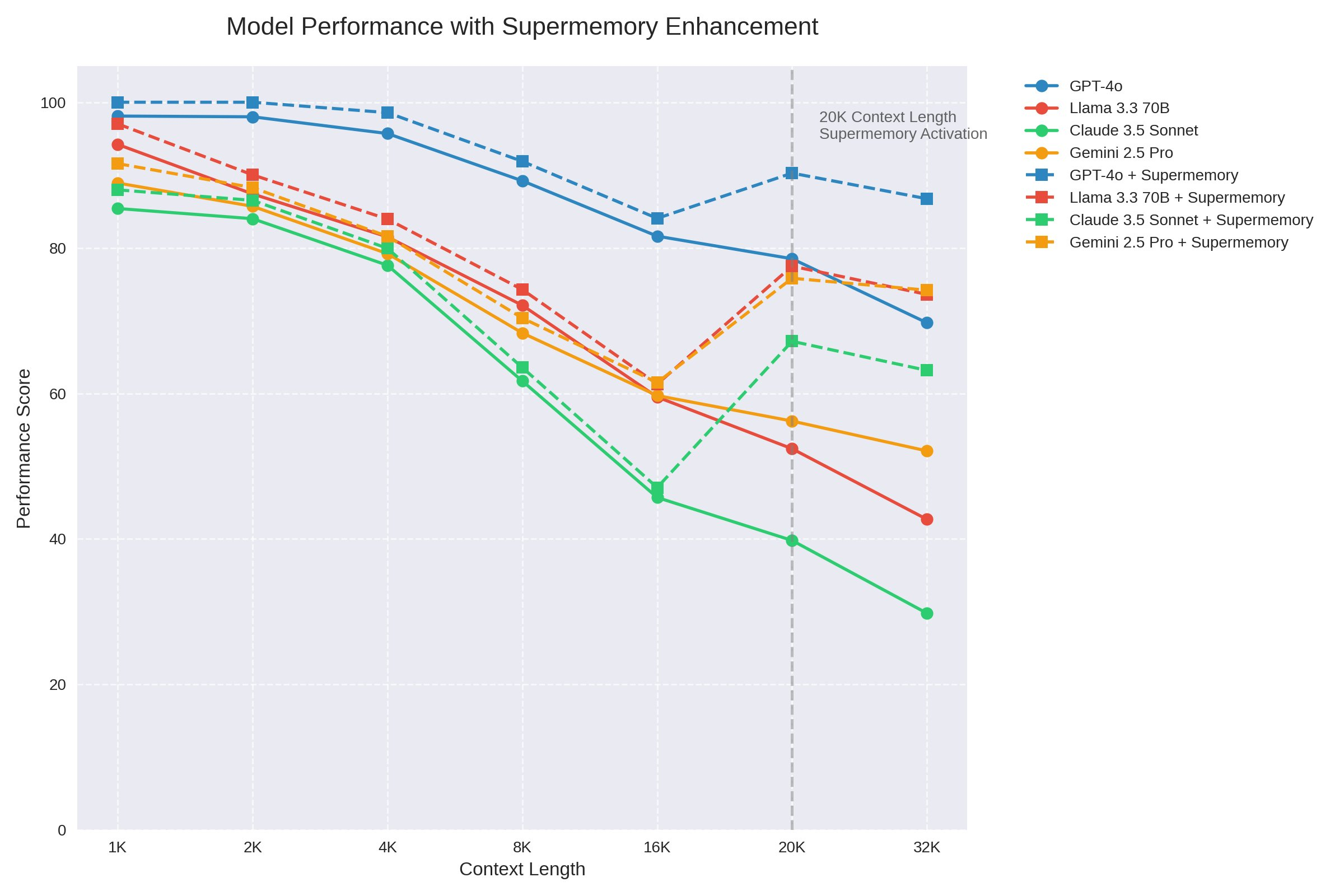
Chat robots (such as ChatGPT, Claude, etc.) have a very limited limitation - they can “remember” limited content because the context window of the model (token limit) has a ceiling, often such as 8k, 32k, or even 128k tokens. Once this length is exceeded, what has been said will be cut off and lost, resulting in:
-
Chat faults. Logical incoherence.
-
User experience is declining. Robot reaction is “forgetting.”
-
claims that ** saves 90% token and costs**, while also enhancing model performance.
-
Very simple to use:** just one line of code to switch**, immediately available.
-
Infinite Chat API, by acting as a transparent agent between ** application and LLM**, transmits only the necessary context necessary to generate a good response, thus avoiding a decline in the performance of large models over a long period of time in the context (e.g. 20K tokens and above).
-
Cost structure: Start free of charge
-
A fixed monthly fee of $20.
-
20k token per thread free, after $1 million token
** It’s like a supermemory hanger:**
-
Automation and compression of dialogue content
-
Dynamic extraction of useful old content to supplement context
-
There’s hardly any delay.
-
It saves a lot of Token’s expenses.
What’s the core of it?
Supermemory embedded the proxy layer in front of your current OpenAI API call and did three things:
1. Transparent Proxy
You originally requested OpenAI’s interface, and now you just change the URL to Supermemory’s address, it’s going to transit your request to LLM, and there’s no intrudable change to your code.
##2. Intelligent parting and retrieval (Chunking + Smart Retrieval)
-
It’ll break down the long dialogue into pieces and keep these synonyms consistent with its home-grown algorithms.
-
When it is necessary to continue the dialogue, it automatically extracts the most relevant contextual fragments from historical records, rather than sending the entire history with your head.
#3 Token Automanager
-
It controls token according to context to prevent the cost from running out of control.
-
To avoid, at the same time, the failure of the request or the interruption of the content.
The way you’re actually using it
Very simple. Take OpenAI interfaces, for example, if: Get API Key to Supermory Console Replace your request URL with: https://api.supermemory.ai/v3/https://api.openai.com/v1 Add x-api-key to the request, fill your Supermory API Key In support of a multilingual client, the official document provides examples of TypeScript and Python.
Performance and cost – practical and not expensive
# # # # # # # # performance advantage
-
Infinite context: Breaking through token limits in models like OpenAI, which can handle any length of dialogue
-
** Cost savings**: as only useful information can be extracted, the use of up to 70% token can be reduced
-
** Almost zero delay**: transmitted as an agent, with requests largely at the same speed
-
** Respond is more stable**: more accurate context extracts and more relevant responses
# # price model
-
Free amount: storage 100,000 tokens free of charge
-
Standard plan: $20 per month, when the free amount is exceeded
-
Increment: $20k token per conversation free of charge and $1 per million tokens thereafter
What if something goes wrong?
If Supermemory makes an error of his own (e.g. failure to retrieve or internal anomalies), it will not affect your request:
-
Will automatically bypass and send the request directly to LLM (e.g. OpenAI)
-
You can still get LLM’s return results, at best in unoptimised context.
-
The response is accompanied by a diagnosis, such as whether the context has been modified, how many tokens have been processed, etc., to facilitate debugging
Support scope and compatibility
Supermemory supports all -compatible OpenAI API models and services, including but not limited to:
- OpenAI GPT-3.5 / GPT-4 / GPT-4o
Claude 3 series of Anthropic
- Other service providers providing OpenAI interface compatibility layer
Moreover, it** does not in itself limit the rate**, but is restricted only by the LLM service you use.
To sum up:
Supermory Information Chat is a highly compatible, non-intrusive “dialogue memory booster” that allows your chat applications to go beyond context limits and be more economical, intelligent and sustainable. Experience: supermemory.chat Documents: https://docs.submemory.ai/infinite-chat