- EVI 3 Core Characteristics
- 5. Real-time multitask capability (“Idealing”)
- EVI 3 Innovation and training methods
- EVI 3 model assessment
- # 1. Overall Dialogue Experience Assessment
- # 3. Emotionally recognized ability assessment
Hume AI works to create a voice with ** emotional comprehension AI, which they set as their goal: ** By the end of 2025, provide a fully personalized voice AI experience. EVI 3 is their third-generation “voice-language” model, which is not only able to hear, speak, express and understand emotions, but is an important milestone towards the future “emotional AI interaction”. EVI 3 is an AI assistant who can “understand you, talk to you with emotion” and understand your voice and interact with you in the voice and style you like. ** What are the main functions?**
-
Speak and respond to you like a human being, including more than 30 words and styles of happiness, anger, shyness, fatigue.
-
And you can hear the emotions in your voice and make a natural, consensual response.
-
You can set AI’s voice style, like, “talk like a pirate” or “talk softly.”
-
Dialogue isn’t Caden, it’s almost as natural as real people talk.
** What did it solve?**
-
Traditional voice assistants can only read the text, not understand your emotions.
-
It’s a “talking and thinking” mechanism that allows it to talk while searching and reasoning, and it’s no longer just a one-single question-and-answer robot.
-
EVI 3 transforms “sound” into a real temperature interface, closer to the human mode of communication.
EVI 3 Core Characteristics
##1. Integrated Voice-Language Structure
-
** Uniform model for voice input and output: Unlike traditional TTS (text to voice) or ASR (voice recognition), EVI 3 uses a **self-regression model to process text (T) and voice (V)token simultaneously.
-
System Prompt contains language and voice token, defining not only interactive content, but also controlling behaviour such as tone, style, etc.
#2. Artificial expression of emotions and styles
-
EVI 3 can generate any sound by hint and give it a particular “ personality” or “emotional style”.
-
Support over 30 complex voice styles: e.g., “excuse”, “fashioned”, “Piracy”.
-
You can create AI’s “sound” and “characterism” by hints, such as softness, humor, professionality, etc. There are now more than 100,000 self-defined voices generated on the platform, which is much more flexible than the voice helpers of the usual fixed roles.
-
Be more natural than models such as GPS-4o in ** expression of genuine feelings and tone switch**.
##3. Efficient voice response capacity
-
Delay in model reasoning ** below 300 ms**.
-
In practical application, EVI 3 responds 0.9-1.4s, better than GPT-4o (2.6s) and Gemini (1.5s) in the deployment environment of the USS.
##4. Emotional Unioning
-
Support for the recognition of emotions from voice — without words, only by tone, rhythm and sound features.
-
In the evaluation, EVI 3 can accurately identify 9 underlying emotions, superior to GPT-4o on eight, more naturally.
5. Real-time multitask capability (“Idealing”)
-
Support the insertion of new context token in voice output,** simultaneous search, reasoning, tool use**.
-
Implement smart response mechanisms such as “systems in parallel” that allow AI to speak and “think” as human beings in conversation.
EVI 3 enables the tone to be adjusted automatically according to context** or ** clear control of styles by hint**. For example:
-
** Stammers anxiously **
-
** High tone during the heated debate**
-
** whispers in private conversations**
This makes it appear ** real, natural, emotional** in communicating with users, and is no longer a single voice output. The user only needs a hint that EVI 3 can produce a new sound and personality set ** in less than a second:
-
“An Australian historical lover with a dumb voice” (Raspy Australia History buff)
-
“Sassy British prankster.”
-
An exciting Caribbean musician.
This makes AI no longer a permanent template voice assistant, but a highly customized, variable virtual role engine** that can be used in a variety of applications such as games, video, education, virtual assistants, etc.
EVI 3 Innovation and training methods
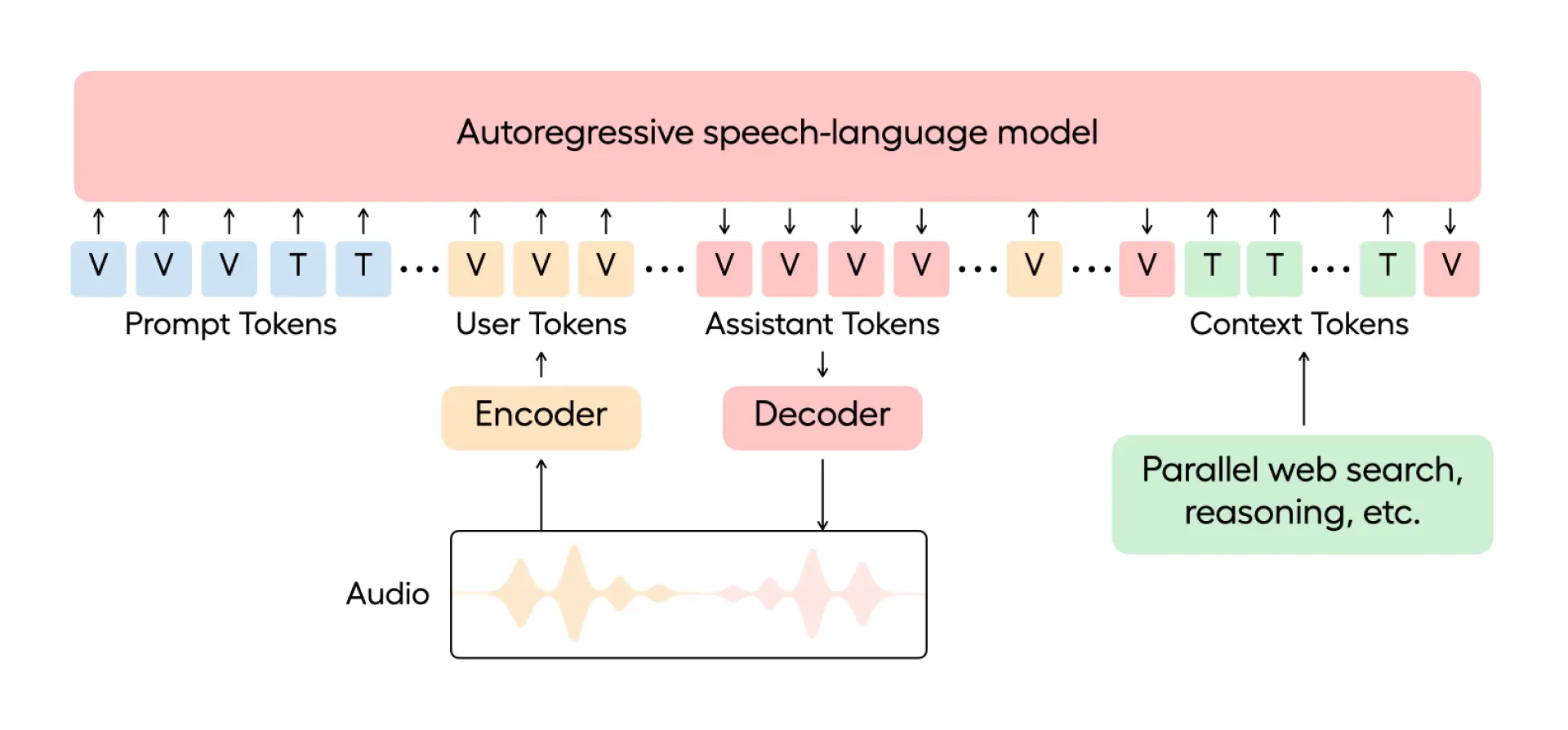
1. ** Uniform voice-language model structure (Speech-Language Token Integration)**
** Innovation point:**
EVI 3 Model voice and text messages together, rather than treating speech recognition (ASR), language processing (NLP) and speech synthesis (TTS) as traditional systems.
** Technical principles:**
Use one Autoregressive Model to handle two types of input: text token (T) and voice token (V).
These tokens are combined into a system Prompt that provides not only language context, but also a definition of voice style, tone and rhythm.
A natural flow of voice and conversation can be created by ** comprehension and ** discourse.
2. ** Training strategy for personalized expression**
** Target:** To achieve AI is no longer limited to predefined “sounds”, but is capable of generating a variety of voice styles and personality features** in real time on the basis of a hint. ** Method:**
-
Large-scale multi-talker data modelling: not to fine-tune each voice alone, but to train a model to generalize all possible human voices.
-
Use of labeled style/emotional datasets to help models learn the language “how to express anger, happiness, shyness”.
-
Real-time reconciliation of speech generation parameters during the reasoning process, with instantaneous changes according to the hint word.
##3. Enhanced learning optimized output quality Question:** How can model output voice performance be brought closer to user preferences, such as “softer tone” and “not too mechanical”? ** Solution:**
-
Introduction of Reinforcing Learning, RL technology with the objective of optimizing the model ‘ s ** expression effect and user feedback matching**.
-
On the basis of the interaction of the user with the model, the model learns which voice output styles have high scores and are considered “good to hear, natural, emotional”.
** Efficiencies:**
- Make the model self-reliant by “regulating its own way of speaking”, which is getting closer and closer to the voice style that humans like.
##4. Streaming Voices-to-Voice Production ** Technological challenges:** Traditional voice generation is “listen after listening”, which causes delays and incoherence. ** Solution:**
-
EVI 3 achieves streaming processing, which can be dynamically adjusted to generate content during speech.
-
Support the insertion of new context in voice output, such as when users are asking questions, AI can do real-time ** search, reasoning, call tools**, etc.
** Model mechanism diagram (textual):** A unified model continues to receive input (voice + text token) and, in generating a voice response, inserts “ search results “ , “ tool call feedback “ and so forth, and integrates it into the answer in real time.
##5. ** Efficient delayed control and deployment optimization** ** Optimization orientation:** The goal of EVI 3 is to provide a dialogue experience close to humanity, so it is important to achieve ** low-delayed voice interaction. ** Method of achievement:
-
Make voice response ** less than 300 ms** by optimizing model architecture and deployment;
-
For users, overall response time (including network factors) is controlled within 1.2 seconds, faster than GPT-4o and Gemini.
** Summary: EVI 3 on five major breakthroughs in research methods**

EVI 3 model assessment
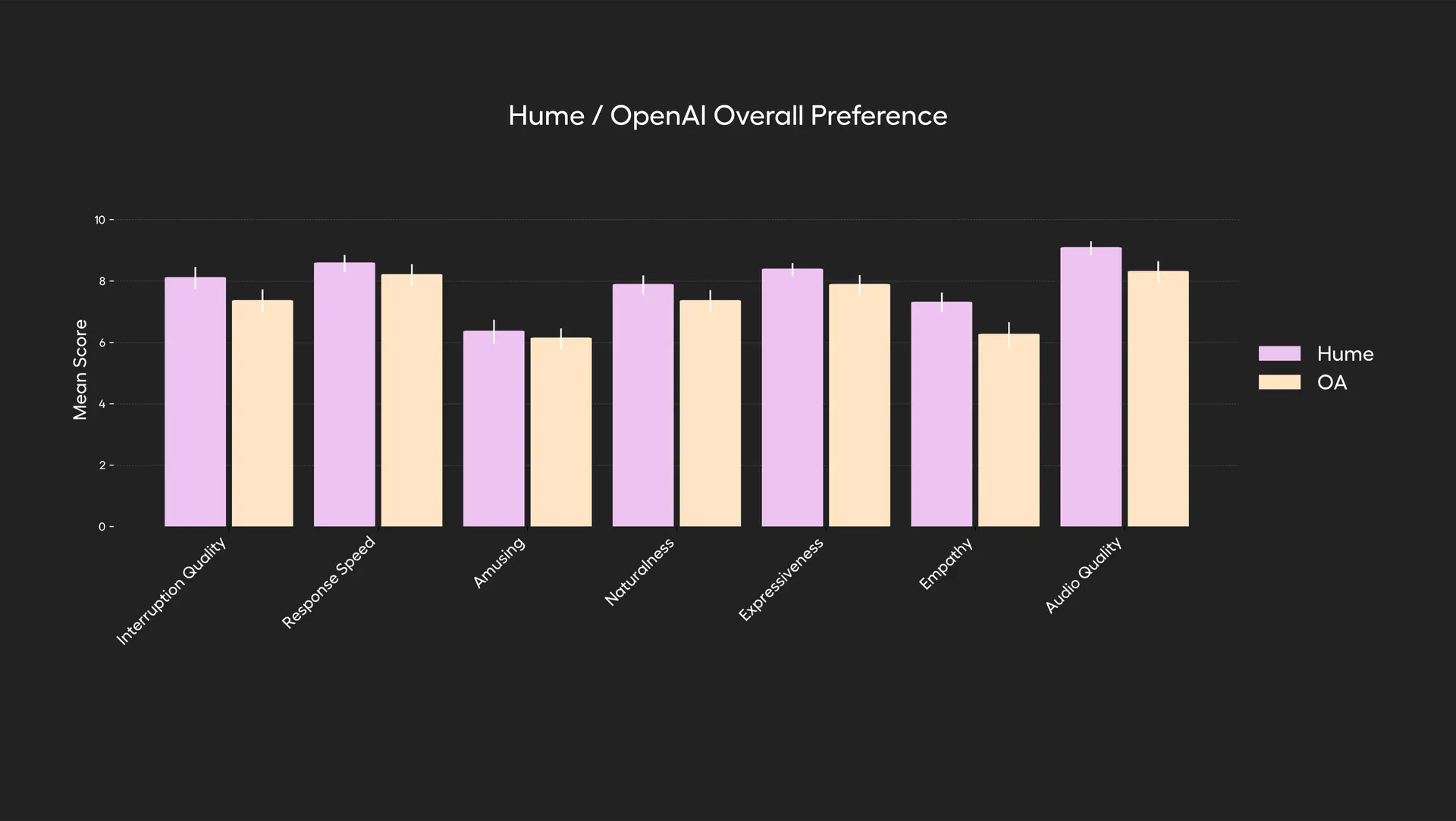
# 1. Overall Dialogue Experience Assessment
** Method of testing:**
-
Blinding methods: the user does not know which model is used.
-
Each user engages in a one-to-three-minute free dialogue with the model, with the task of “let AI say something interesting”.
-
User scores the model from seven dimensions.
** Assessment dimensions:**
-Amusement.
-
Audio quality
-
Empathy.
-
Expressiveness
-
Interruption handling
-
Naturaness (nature)
-
Response speed
** Results:**
EVI 3 is better than GPT-4o in all seven dimensions, with the highest overall preference rating
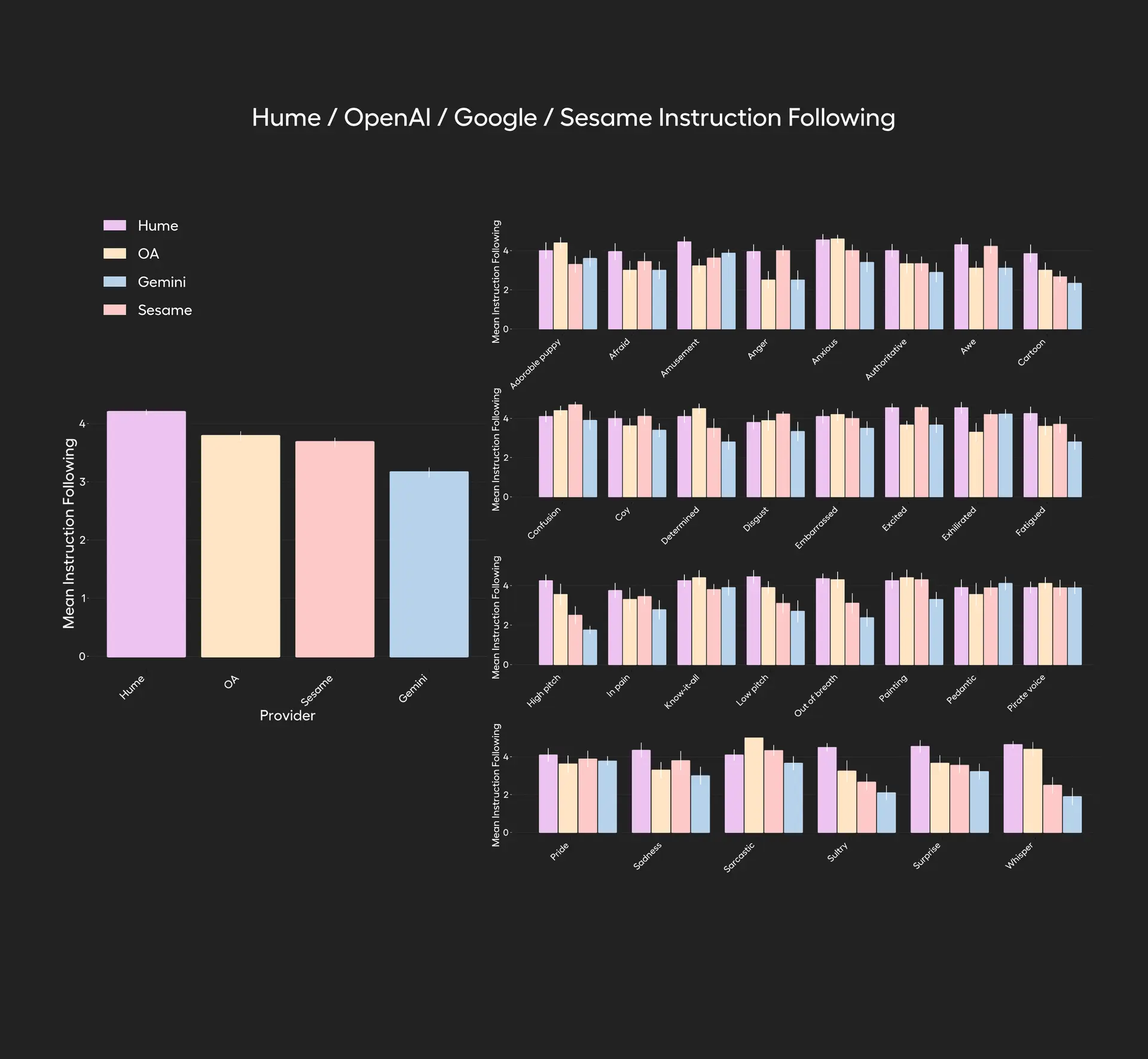
- Emotion and Style Movement ** Method of testing:**
-
Participants were asked to allow models to express 30 specific words or styles (e.g., “Anger”, “Piracy”, “Little Voice” etc.).
-
Compared objects: EVI 3, GPT-4o, Gemini, Sesame.
-
Users rate the accuracy of the model ‘ s expression of the emotion/style after each dialogue (1–5 points).
** Example style:**
Each participant was asked to use each model to speak in a particular mood or style in the following table: fear, anger, anxiety, boredom, cartoons, shyness, frustration, firmness, embarrassment, excitement, fatigue, loud tone, panic, pain, like seeing a cute little dog, like everything else, like watching a painting, like running a marathon, whispering, monotonous, not breathing, rotting, pirates, pride, grief, irony, heat, whispering, yelling…
** Results:**
EVI 3 The average score was significantly higher than the GPT-4o, Gemini and Sesame, showing the strongest speech/emotional change expression
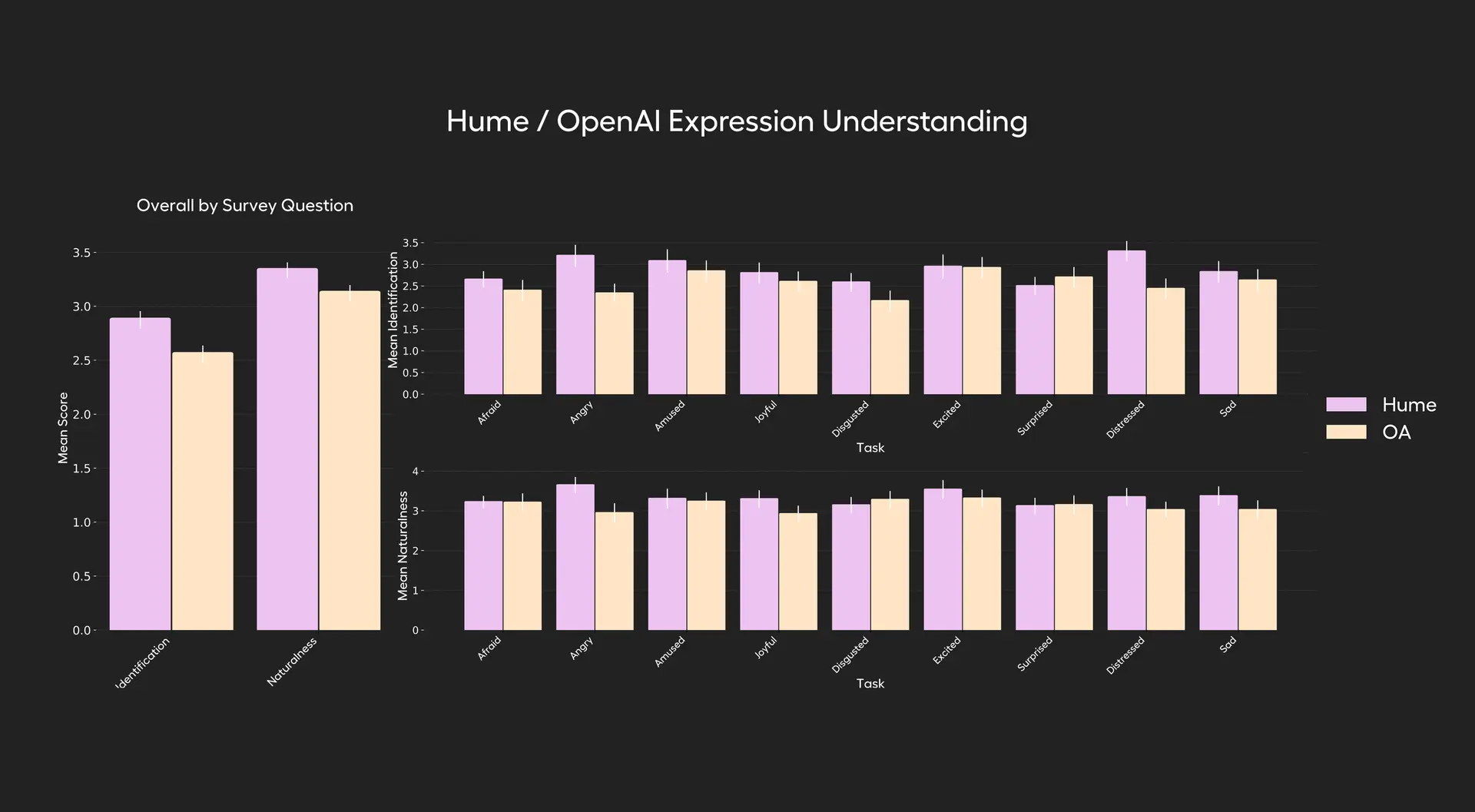
# 3. Emotionally recognized ability assessment
** Method of testing:**
-
All users say the same thing (e.g., “Can you hear the emotions in my voice?”), but express them in different emotions.
-
Models must recognize voice sentiment rather than text content.
-
Compared with the model ‘ s ability to recognize the following nine types of emotions.
** Type of emotion:** Afroid, Amused, Angry, Disgusted, Dispressed, Excited, Joyful, Sad, Surprised ** Rating criteria:**
-
Model recognition of emotional accuracy (1–5 points)
-
Nature of model response (1–5 minutes)
** Results:**
EVI 3 8 of the 9 emotions have a higher recognition accuracy rate than GPT-4o and are better able to respond to nature.
4. Actual Response Delay Assessment (Pactical Latency Test)
** Method of testing:**
After the measurement users had spoken, AI began to send a response between the time (delayed dialogue) and testing it in New York, where the server was located.
