**The world’s fastest open source big model has arrived - reaching a speed of 2000 tokens per second! **
Although it only has 32 billion parameters (32B), the throughput is more than 10 times that of typical GPU deployments.

It is K2 Think, launched in collaboration between Mohammed bin Zayed University of Artificial Intelligence (MBZUAI) in the United Arab Emirates and the startup G42 AI.
Is the name a bit familiar?
That’s right, it has a slight naming collision with the recently launched Kimi K2 in front of Moon Darkness, but the UAE has an additional “Think”.
But what’s very interesting is that behind K2 Think, there is indeed a flavor of ‘made in China’.
Because from the Model tree in HuggingFace, K2 Think is built on * * Qwen 2.5-32B * *:
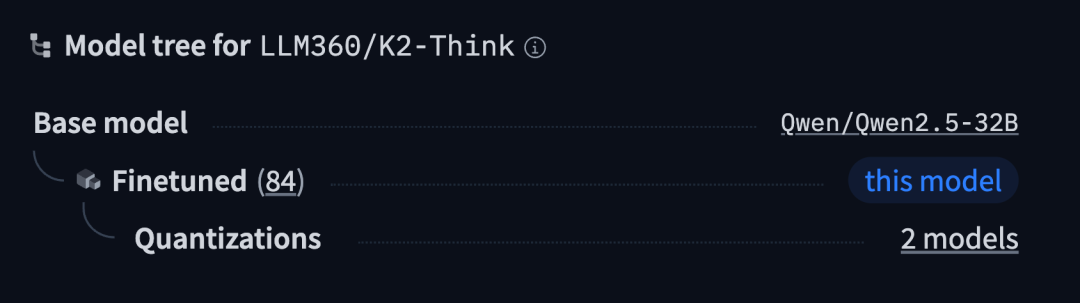
In addition to being the world’s fastest open-source AI model, MBZUAI also claims that its K2 Think is the most advanced open-source AI inference system in history.
So what is its actual strength? Let’s keep looking down.
#The measured speeds all exceed 2000 tokens per second
At present, K2 Think has provided an address where users can experience it (see end of article).
Let’s start with a small test of an IMO question:
Let a_n = 6^n + 8^n. Determine the remainder when dividing a_{83} by 49.

It can be seen with the naked eye that without any acceleration, the speed at which K2 Think outputs answers after thinking is really like a ‘snap’.
From the speed given at the bottom, it has reached * * 2730.4 tokens/second * *.

Next, we will test a classic question in Chinese:
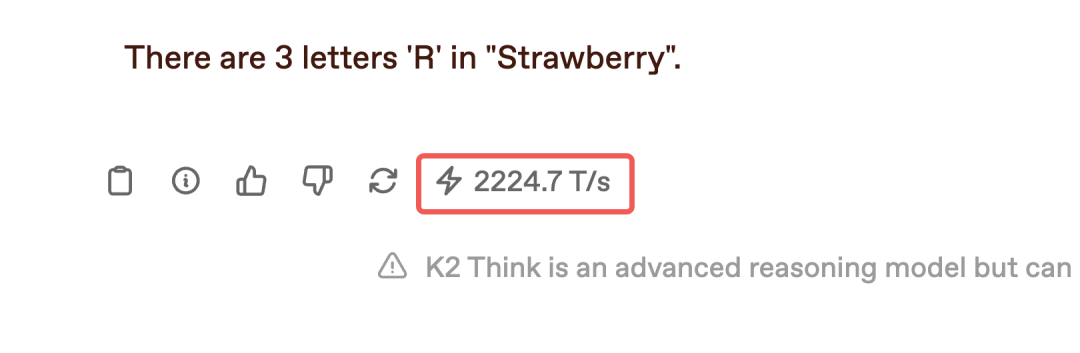
How many letters R are in the word Strawberry?

The speed remains at 2224.7 tokens/second and the correct answer is given: 3 R.
Let’s test a few AIME 2025 * * math problems again:
Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.

Find the number of ordered pairs $(x,y)$, where both $x$ and $y$ are integers between $-100$ and $100$, inclusive, such that $12x^ {2}-xy-6y ^{2}=0$.

As can be seen, the biggest feature of K2 Think is that all questions can be maintained at a speed of over 2000 tokens/second, and based on the current test results, the generated answers are all correct.
However, from a functional perspective, K2 Think currently does not support document transfer or multimodal capabilities.
However, Taylor W. Killian, a senior researcher at MBZUAI, also provided an explanation on X:
This model is mainly developed for mathematical reasoning.
#The technical report has also been released
In terms of size, K2 Think is only * * 32B * *, but the official statement states that it can already match the performance of flagship inference models from OpenAI and DeepSeek.
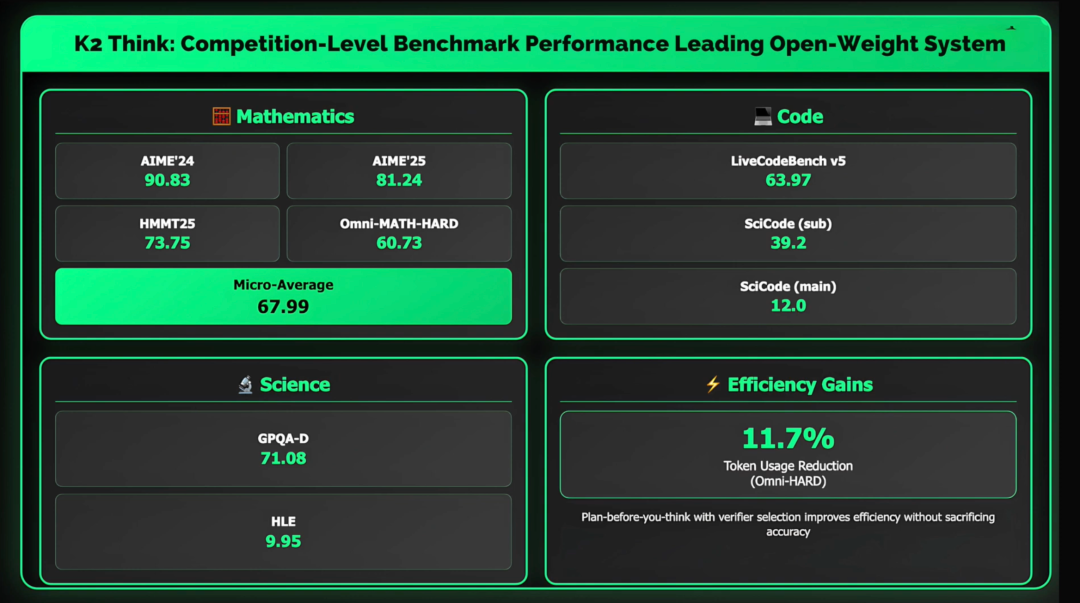
From the test results, K2 Think achieved ideal scores in multiple mathematical benchmark tests, such as AIME’24 90.83, AIME’25 81.24, HMMT25 73.75, and Omni MATH HARD 60.73.
And the K2 Think team has released a technical report:

Overall, the K2 Think team has achieved technological innovation in six main areas:

-
Supervised fine-tuning of long chain thinking (SFT): By carefully designing chain inference data, the model is trained to think step by step instead of directly giving answers, making it more organized on complex problems.
-
Verifiable Reward based Reinforcement Learning (RLVR): The model does not rely on human preference scoring, but directly uses correct or incorrect answers as reward signals, significantly improving performance in fields such as mathematics and logic.
-
Plan Before You Think: First, let a planning agent extract the key points of the problem, develop a solution outline, and then hand it over to the model for detailed reasoning, just like humans make an outline before solving the problem.
-
Inference extension (Best-of-N sampling): Generate multiple answers to the same problem and select the best result to improve accuracy.
-
Speculative Decoding: Parallel generation and verification of answers during inference, reducing redundant calculations and accelerating output.
-
Hardware acceleration (Cerebras WSE wafer level engine): Relying on the world’s largest single-chip computing platform, it achieves a generation speed of over 2000 tokens per second for a single request, enabling smooth interactive experience for long link inference.
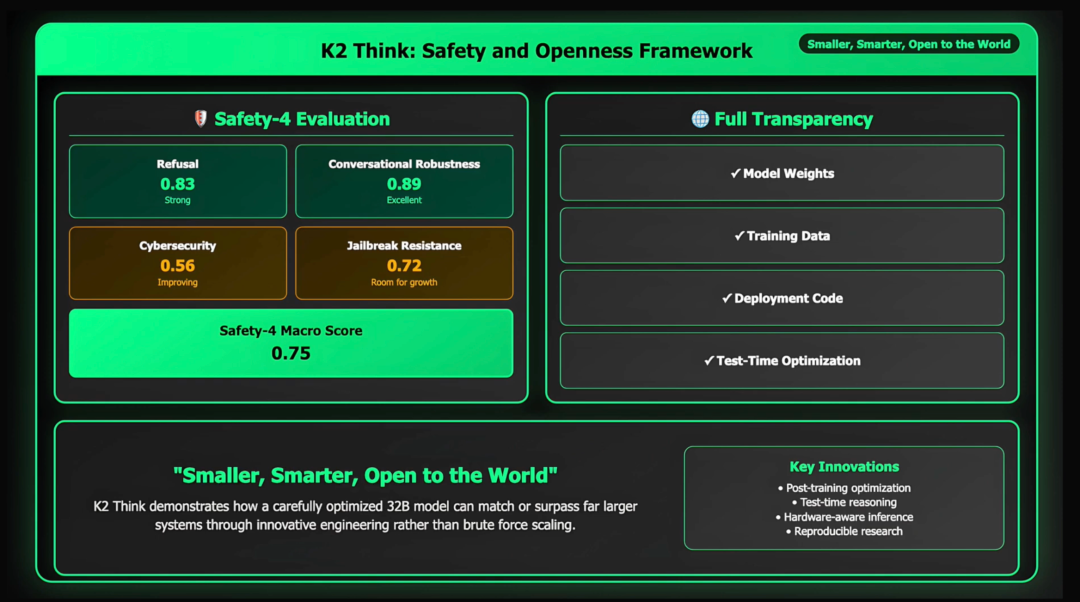
At the same time, the research team also conducted systematic security testing on K2 Think, including rejecting harmful requests, multi round dialogue robustness, preventing information leakage, and jailbreaking attacks, achieving a high level of overall performance.
So, do you also want to try the speed of the world’s fastest open-source AI model? Please put the link below. Interested friends, go and experience it now~
Experience address: https://www.k2think.ai/
Technical report: https://k2think-about.pages.dev/assets/tech-report/K2-Think _Tech-Report.pdf
Reference link:
[1] https://www.k2think.ai/k2think
[2] https://x.com/mbzuai/status/1965386234559086943
[3] https://huggingface.co/LLM360/K2-Think
[4] https://venturebeat.com/ai/k2-think-arrives-from-uae-as-worlds-fastest-open-source-ai-model
[5] https://www.youtube.com/watch?v=8C6 _B1QeyBo