#The latest achievement of Transformer author’s startup company: Open source new framework breaks through the bottleneck of evolutionary computing, sample efficiency skyrockets by tens of times
**Open source framework improves sample efficiency by tens of times! **
The same task used to require thousands of evaluations, but now it can be completed with 150 samples.
Transformer author Llion Jones, with his startup Sakana AI, is once again causing trouble. (doge)
The latest open-source framework, ShinkaEvolve, allows LLM to optimize their own code while also balancing efficiency, like installing an “acceleration engine” for evolutionary computing.
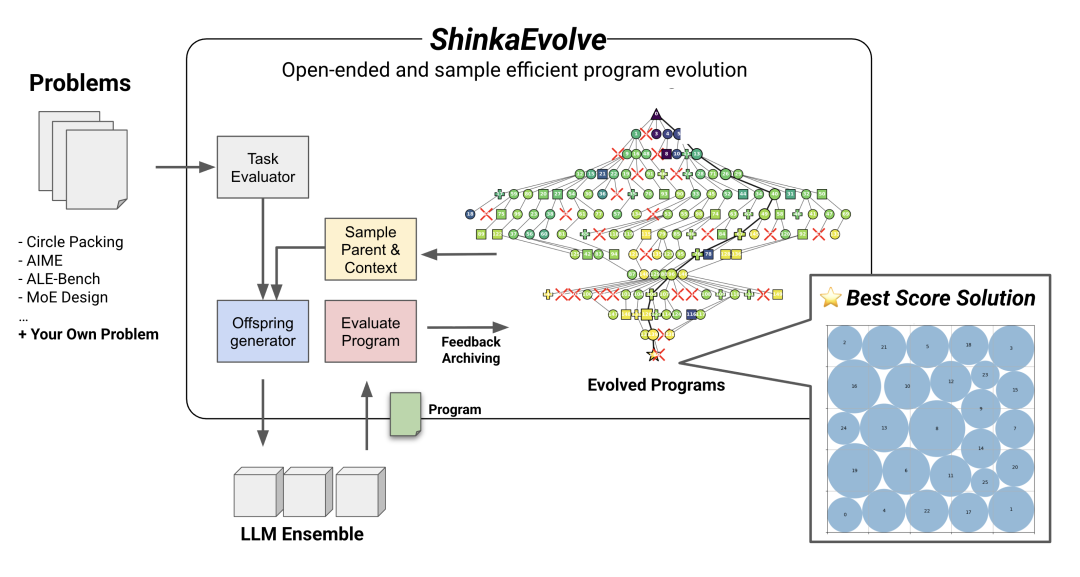
Mainly through three architectural innovations, it has demonstrated its performance advantages in multiple tasks such as mathematical optimization, intelligent agent design, and competitive programming.
It can be said that the performance is comparable to Google’s AlphaEvolve, but the samples are more efficient and also open-source!
Below are more specific details.
##Introduction of Three Innovative Technologies
Imagine how many steps would it take for LLM to find the optimal solution to a problem through evolutionary computation?
Taking AlphaEvolve as an example, first generate a hypothesis, then run experiments to verify and learn from it, and then propose better hypotheses… The cycle repeats, constantly approaching the truth.
Even the simplest experiment would require enormous resources, high computational costs, and significant time consumption.
The ShinkaEvolve framework addresses the aforementioned issues by achieving dual program evolution of performance and efficiency, with three key technologies at its core:
+* * Balanced exploration and utilization of parental sampling techniques**
This technology ensures the effectiveness of evolutionary direction through a layered strategy and the fusion of multiple methods.
On the basis of the evaluated program, the framework uses the “island group model” to divide the population into independent subgroups for parallel evolution. The subgroups also periodically transfer knowledge and retain the optimal solution to ensure uniqueness.
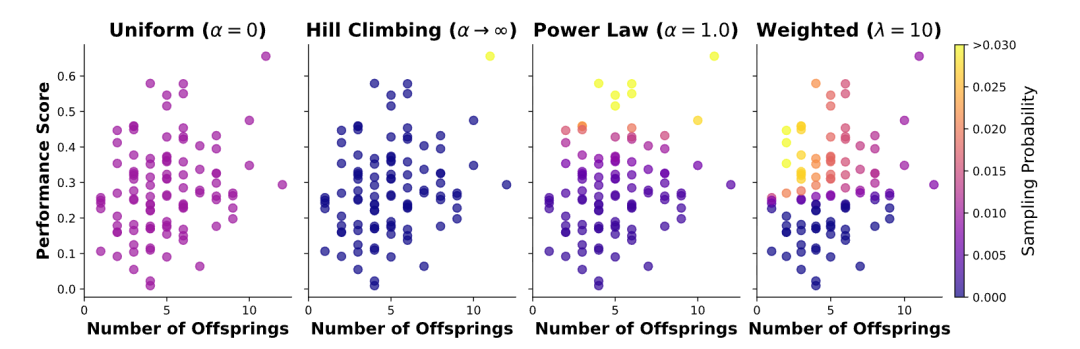
Specifically, it involves uniformly selecting island group IDs during sampling, and then combining top-K high-quality solutions with random samples to select parents and heuristic programs. Through a multi strategy model of power-law sampling * (probability allocation based on fitness) * and weighted sampling * (fusion performance and novelty) *, it balances known good solutions and explores new ideas.
+Code novelty rejection sampling**
To reduce the ineffective computation of duplicate or low novelty variants generated by LLM, the framework adopts a secondary filtering mechanism of * * embedding similarity screening+LLM arbitration * *.
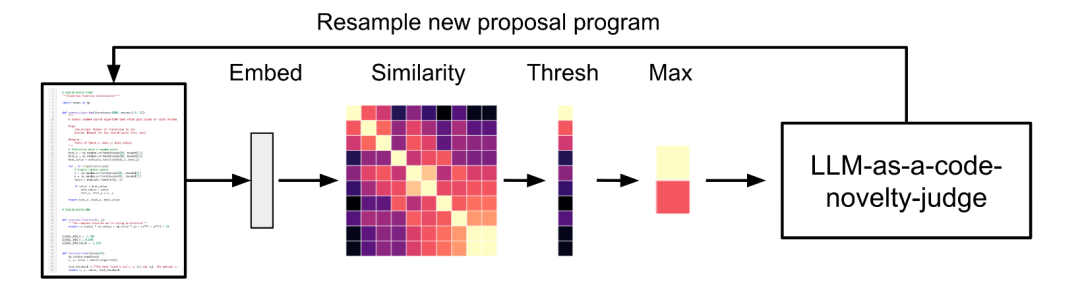
Firstly, the program’s mutable parts are encoded by embedding the model, and the cosine similarity with the existing program is calculated. If it exceeds the threshold (such as 0.95), additional LLM is called to evaluate its semantic uniqueness, and only the truly novel candidate solutions are retained to ensure exploration efficiency.
+LLM integrated selection strategy based on multi arm slot machine**
The framework is based on the dynamic scheduling model of UCB1 algorithm to address the performance differences of different LLMs in tasks and evolutionary stages.
That is to say, two evaluation metrics are set for each LLM: an access counter that records usage times and an estimated score that evaluates expected performance.
Then, when the model generates new improvements, the score is updated in real-time by comparing the magnitude of the improvements, and the significant changes in the reinforcement contribution weight are normalized using an exponential function to dynamically select the most suitable LLM at the moment.

The final operation of the entire framework revolves around * * sampling, mutation, and feedback * * to form a closed loop, providing a new paradigm for cost reduction and efficiency improvement in LLM evolutionary computation.
##Realize an order of magnitude improvement in sample efficiency
In addition, researchers also conducted comparative experiments in four fields (mathematical optimization, agent design, competition programming, LLM training) to verify the performance of the ShinkaEvolve framework.
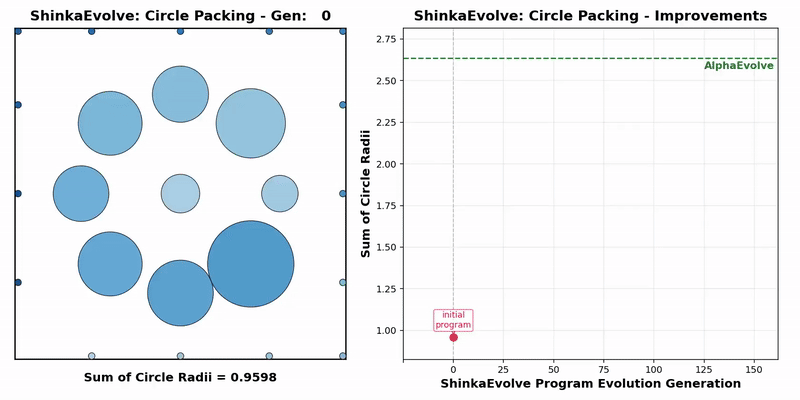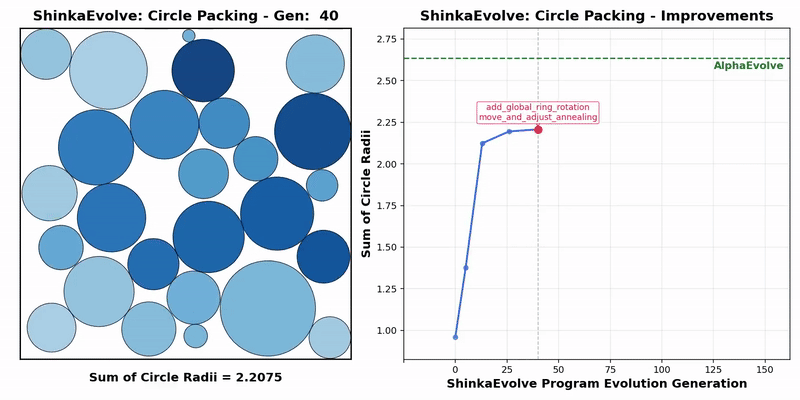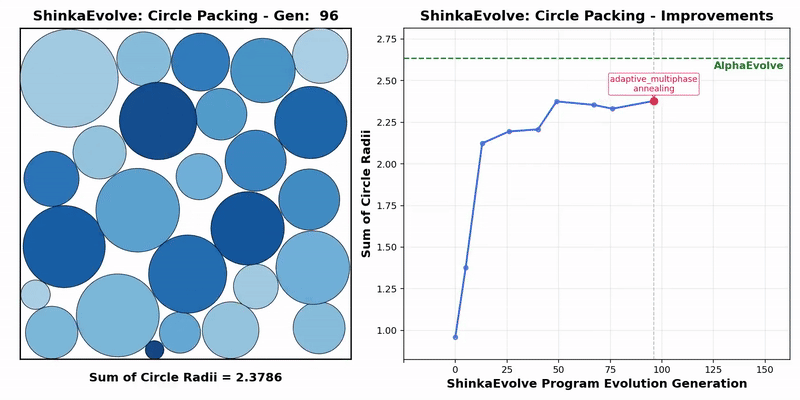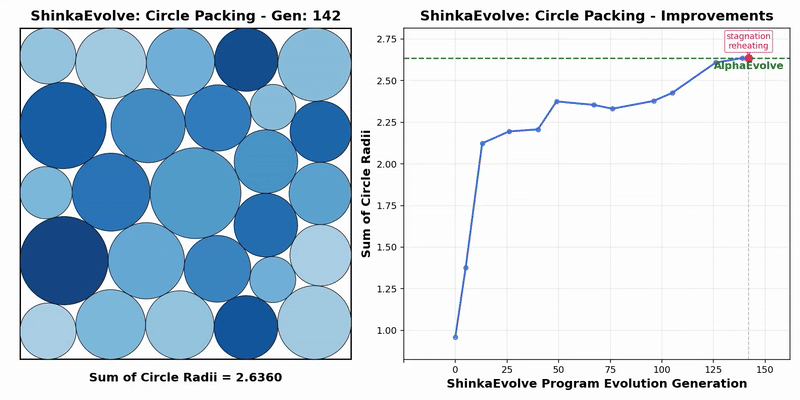
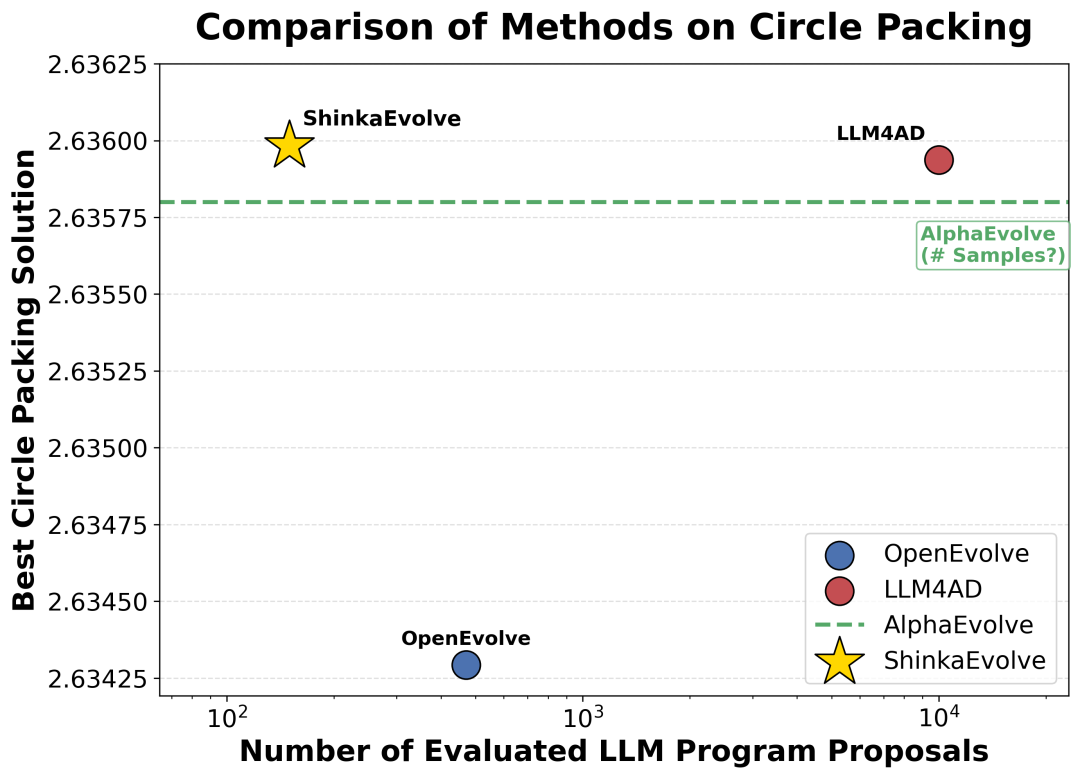
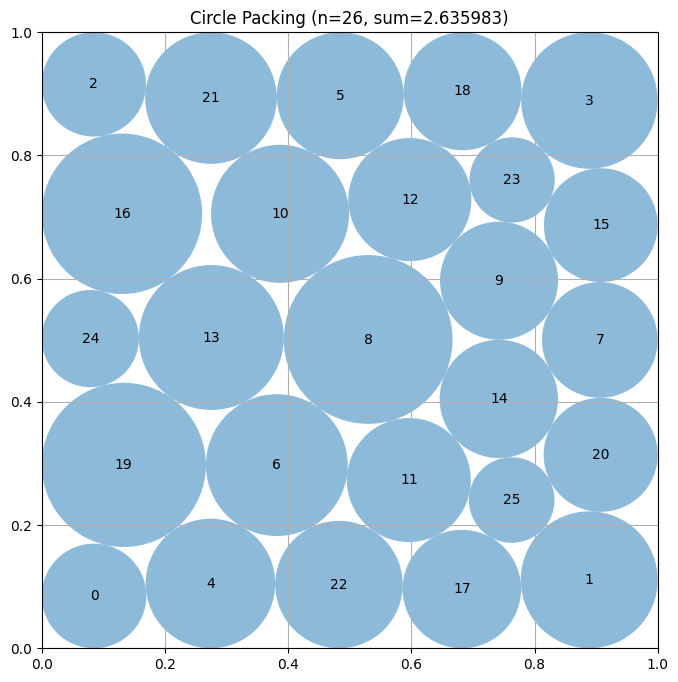
Firstly, in the mathematical optimization problem, the experiment requires placing 26 circles within a unit square to maximize the sum of their radii, while ensuring that there are no overlapping circles and that all circles are completely contained within the boundaries of the square.
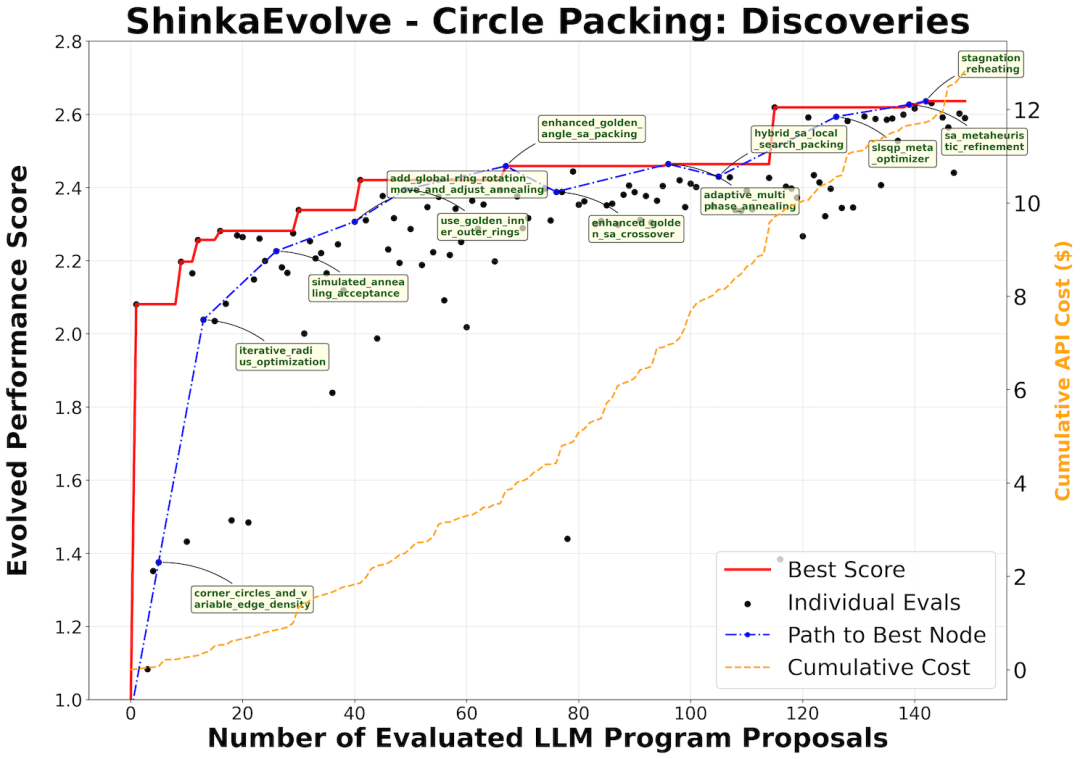
The results indicate that ShinkaEvolve requires only 150 evaluations, while AlphaEvolve requires thousands of evaluations, significantly improving sample efficiency.
At the same time, the entire evolutionary process presents three different stages, including the rapid improvement stage of quickly discovering basic radius optimization strategies, the exploration stage of continuously obtaining incremental benefits, and the final convergence stage, ultimately breaking through the balance bottleneck between space utilization and radius sum.
In the design of Agent, experiments were conducted on 30 mathematical reasoning problems for the 2024 AIME competition. A model based on gpt-4.1-nano was proposed, with a maximum of 10 LLM queries called.
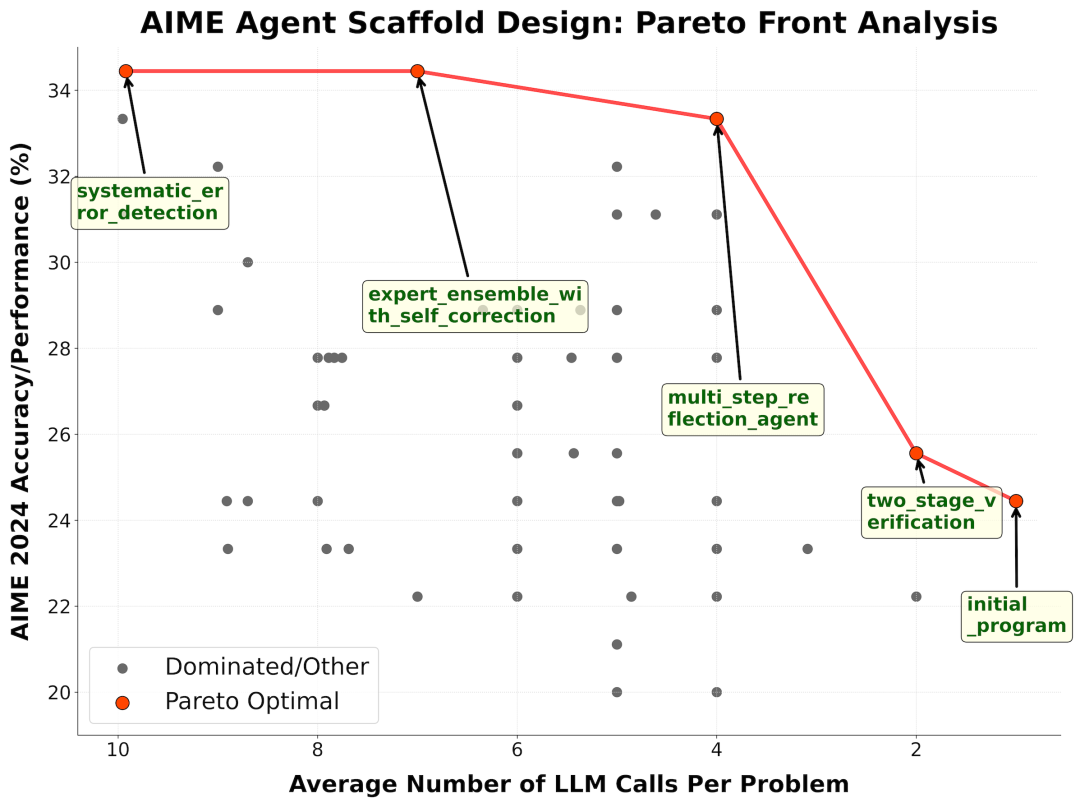
The experiment found that the framework design of ShinkaEvolve is significantly better than the model baseline, including simple single query agents and complex majority voting methods.
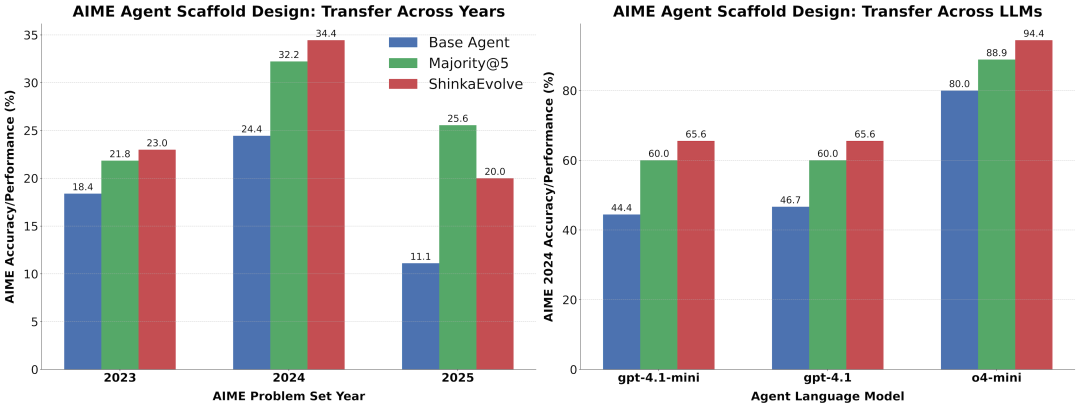
Among them, 7 LLM queries generated the maximum performance, and it also performed stably on low pollution 2023 and unseen 2025 AIME competition questions, and was compatible with various models such as gpt-4.1-mini and o4 mini.
In addition, evaluate ShinkaEvolve on the ALE Bench competitive programming benchmark to observe its ability to solve problems in dynamic programming, graph theory, and combinatorial optimization.
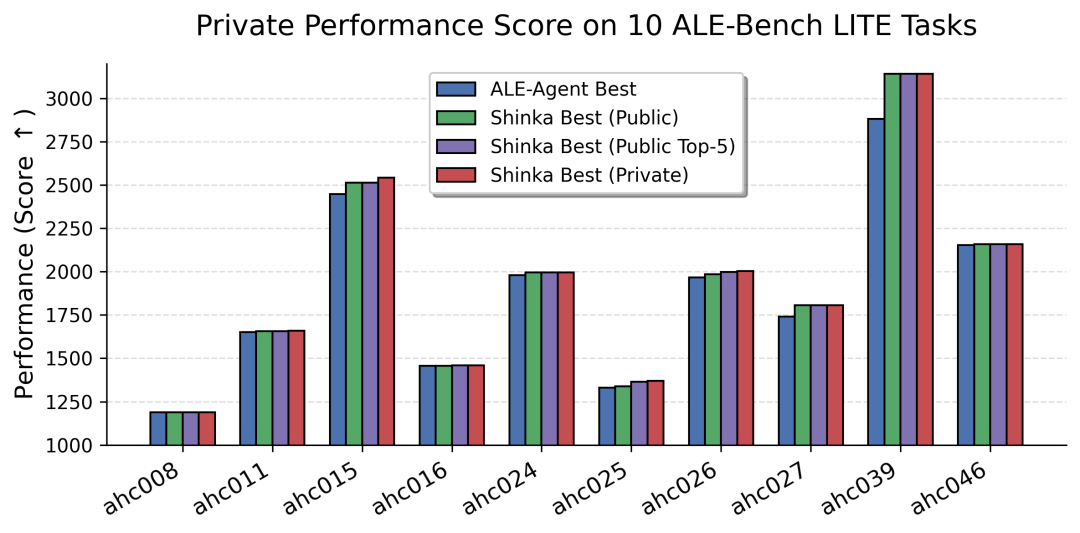
The results showed that the average score of the 10 AtCoder competition questions increased by * * 2.3% * *, with the ahc039 task rising from 5th place to 2nd place and having the potential for competition awards. The optimization of related code also focuses more on detail improvement and does not rely on large-scale refactoring.
The researchers are also evaluating ShinkaEvolve on the task of * * Mixed Expert * * (MoE) * * Load Balancing Loss Function * *, requiring the evolution of Load Balancing Loss * (LBL) * with 556M parameter MoE and validation of generalization with 2.7B parameter MoE, ultimately balancing cross entropy loss and expert balancing.
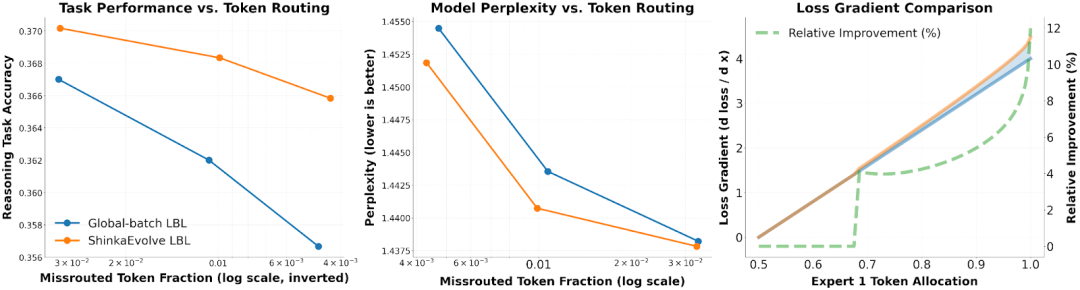
The results showed that the new LBL generated by ShinkaEvolve exhibited higher accuracy and lower perplexity on all 7 downstream tasks, and the advantage became more significant as the regularization coefficient λ increased.
The final experiment fully proves that the new framework can effectively achieve an order of magnitude improvement in sample efficiency, as well as wide applicability across tasks in different fields. Its open source feature will further reduce the threshold for technical use.
*Paper link: https://arxiv.org/abs/2509.19349 *
*Code link: https://github.com/SakanaAI/ShinkaEvolve *
*Reference link:
[1] https://x.com/SakanaAILabs/status/1971081557210489039
[2] https://sakana.ai/shinka-evolve/ *