Just released the final version of V3.1, DeepSeek’s latest model is back!
**DeepSeek V3.2-Exp * * has just been officially launched, introducing a new attention mechanism - DeepSeek Sparse Attention * *.
We also open-source a more efficient version of Tile Lang GPU operator!
##New Attention Mechanism
DeepSeeker V3.2-Exp is built on the recently updated DeepSeeker V3.1-Terminus, with the core innovation being the introduction of the DeepSeek Sparse Attention (DSA) mechanism.
DSA has implemented a fine-grained attention mechanism for the first time, which can significantly improve the efficiency of long text and inference without affecting the output performance of the model.
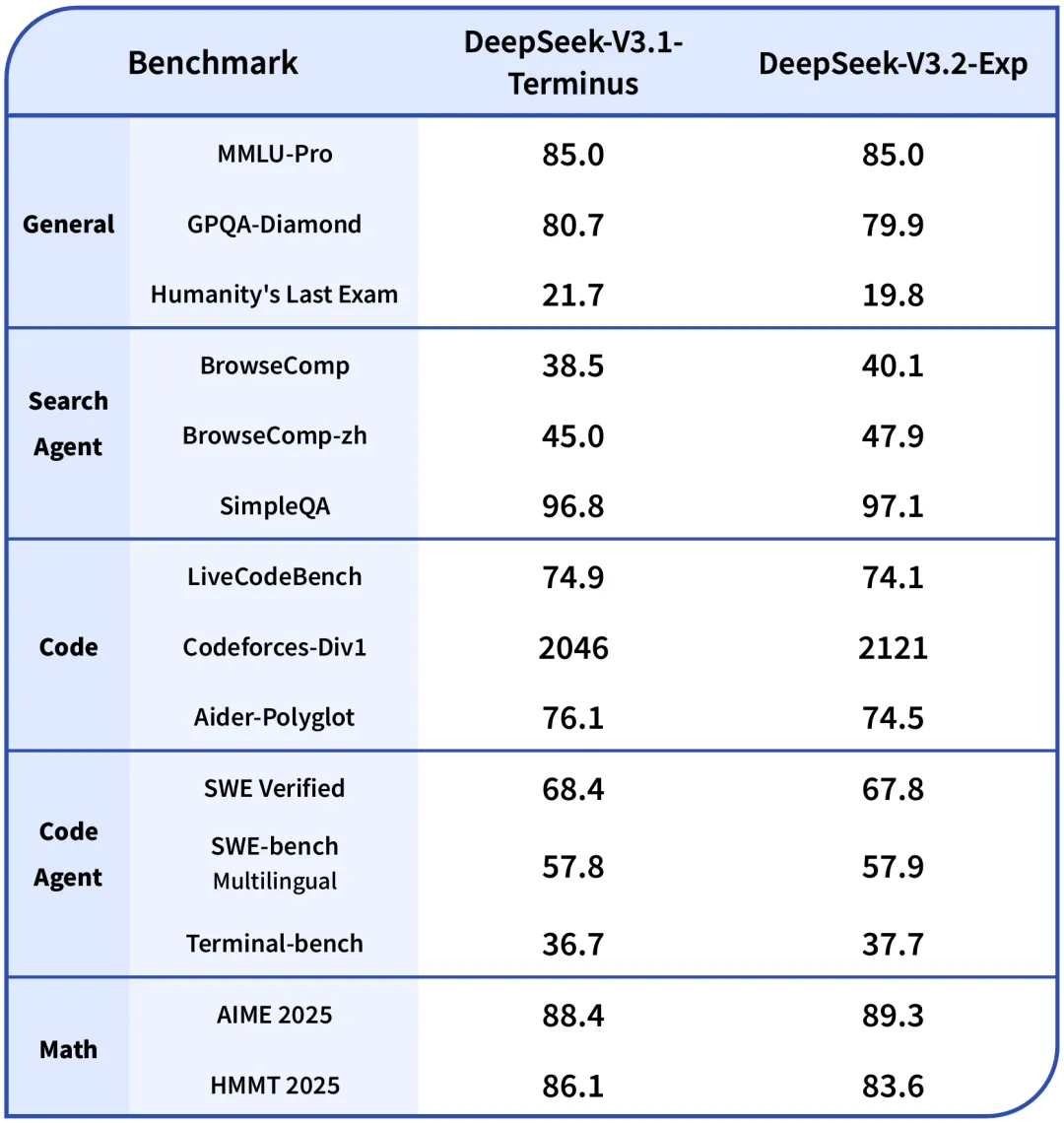
 Compared with the recently updated DeepSeek-V3.1-Terminus, DeepSeek-V3.2-Exp and V3.1-Terminus are basically on par in public evaluation sets in various fields.
Compared with the recently updated DeepSeek-V3.1-Terminus, DeepSeek-V3.2-Exp and V3.1-Terminus are basically on par in public evaluation sets in various fields.
V3.1 Terminus is an enhanced version based on DeepSeek V3.1, which iteratively improves stability, tool calling capabilities, language consistency, error correction, and other aspects.
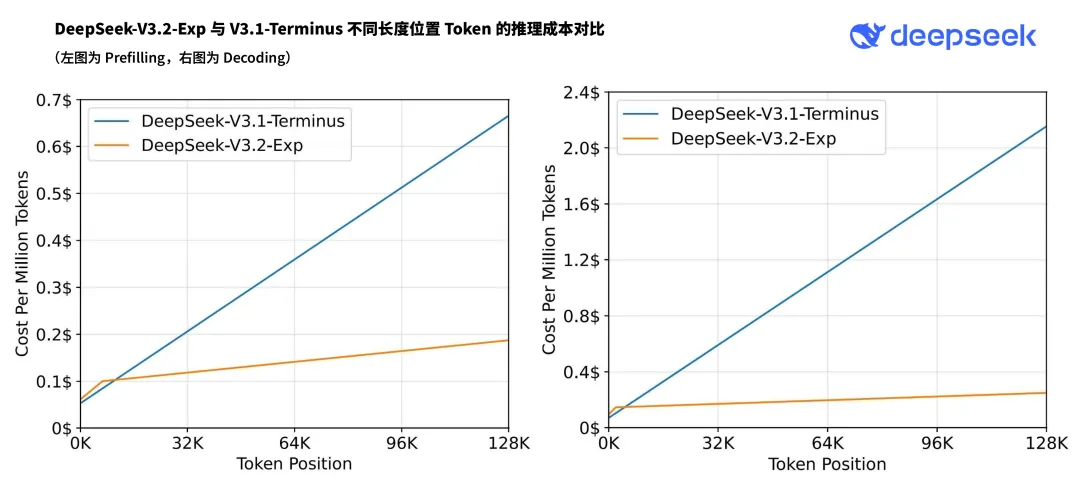
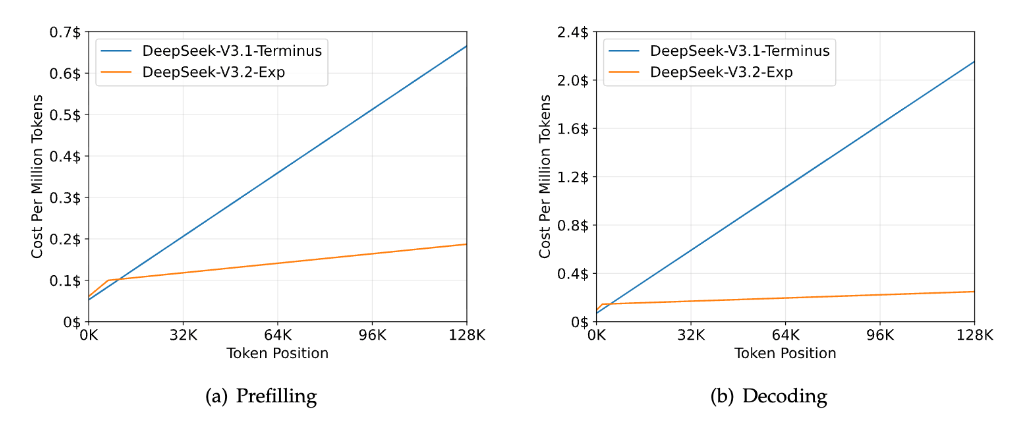
In addition, the paper mentions that the inference cost of the model using DSA is significantly lower than that of DeepSeek-V3.1-Terminus when processing 128K long contexts, especially in the decoding stage.
##TileLang&CUDA dual version operator open source
DeepSeek also stated that in the process of developing new models, it is necessary to design and implement many new GPU operators.
They use the high-level language TileLang for rapid prototyping development, and in the final stage, use TileLang as the precision baseline to gradually implement more efficient versions using the underlying language.
Therefore, the main open source operators for V3.2 include TileLang and CUDA versions.

Guide the way ↓
HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
ModelScope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
paper
https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek _V3_2.pdf