#Fine tuned alignment of large models, increasing realism by 25.8% and refreshing SOTA! Token level precise editing, plug and play without training
A new method to improve the alignment ability of large models, with a 25.8% increase in authenticity indicators on TruthfulQA tasks, refreshing the current optimal performance!
The method is called Token Aware Editing (TAE) and is a token aware inference representation editing method.
This method systematically solves the problems of traditional representation editing techniques at the token level for the first time, without the need for training, plug and play, and can be widely applied in dialogue systems, content review, bias mitigation, and other scenarios.

In the era of widespread application of large models, how to make the model output more in line with human values (such as authenticity, harmlessness, fairness) has become a key challenge. Traditional methods often rely on a large amount of data fine-tuning, which is costly, inefficient, and prone to introducing new risks.
In recent years, directly editing the internal activation values of large language models (LLMs) has been proven to be an effective method for aligning inference, which can efficiently suppress negative behaviors such as model generation errors or harmful content, thereby ensuring the security and reliability of LLM applications.
However, existing methods ignore the misalignment differences between different tokens, resulting in alignment direction deviations and a lack of flexibility in editing strength.
As a result, a research team from Beihang University proposed this method at EMNLP 2025.
In the future, the team plans to expand TAE to multi-dimensional alignment (such as optimizing authenticity and harmlessness), and explore its integration with training methods such as SFT and RLHF to promote the development of larger models towards safer and more reliable directions.
##TAE: Fine grained intervention from “sentence” to “word”
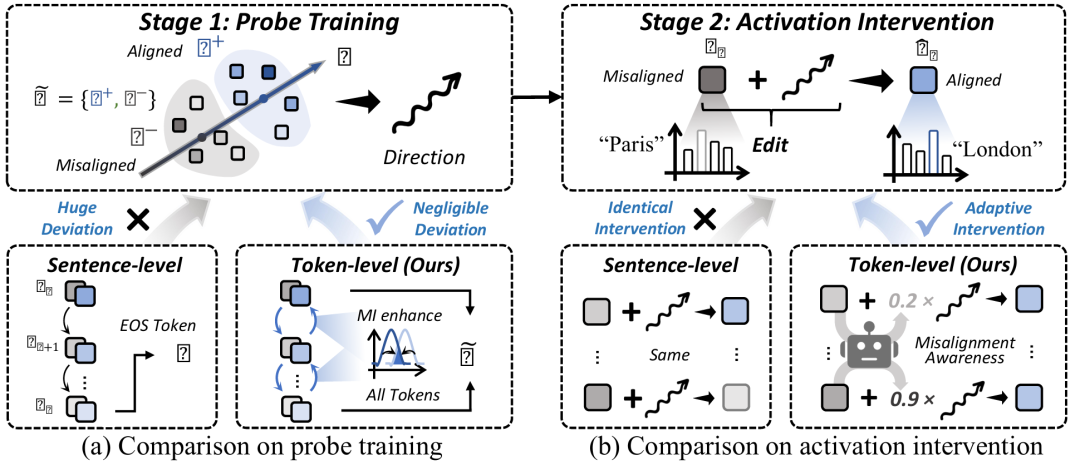
The research team pointed out that previous studies on representation editing (such as ITI, TruthX, etc.) mostly focused on activation value editing at the sentence level, and there were problems in both the exploration of editing direction and internal representation editing stages
+Deviant Alignment Direction: Using only the last token to represent the entire sentence lacks comprehensive information and the learned editing direction is inaccurate.
+Inflexible Editing Strength: Editing all tokens’ equally ‘without accurately correcting truly’ erroneous’ tokens.
To address the aforementioned issues, the team proposed Token Ware Editing (TAE), which consists of two core modules:
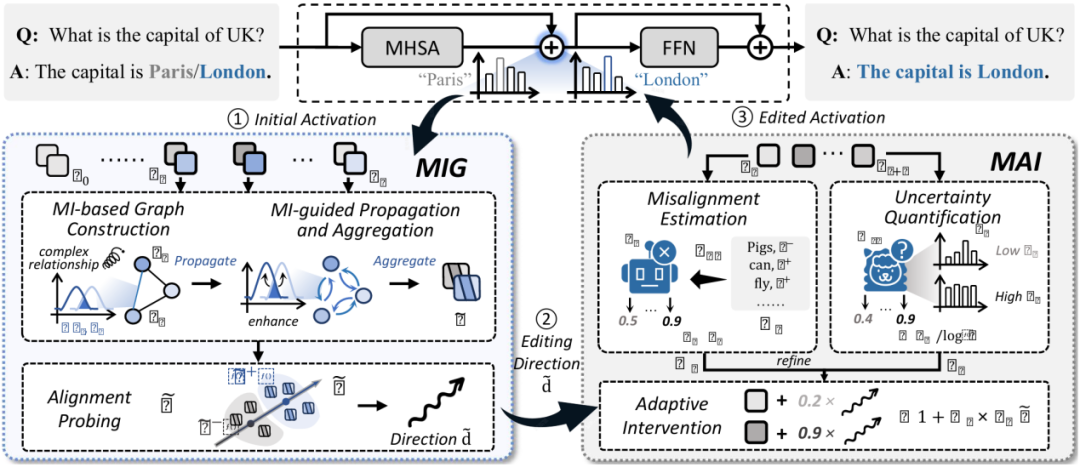
1 Mutual Information-guided Graph Aggregation (MIG)
Traditional sentence level probes use the activation value of the last token (usually a period or other identifier) to represent the semantics and alignment status of the entire complex sentence. However, although LLM’s self attention mechanism allows the last token to perceive information from all previous tokens, this perception may suffer from information loss and local understanding limitations. Therefore, the ‘alignment direction’ learned solely based on it may be biased and not a universal direction. The goal of the MIG module is to enhance the characterization ability of activation values, thereby training better probes and finding more accurate editing directions.
+Building Token Relationship Diagram: Utilizing Mutual Information to quantify the correlation between Token activation values and construct an information interaction diagram;
+Multi level information aggregation: Through multi round graph propagation, the semantic information of all tokens is fused to generate more representative enhanced activation representations;
+Accurate alignment direction detection: training the detection head based on enhanced representation to accurately identify and align the relevant intervention directions
2 Misalignment-aware Adaptive Intervention (MAI)
During inference intervention, traditional methods apply the same editing strength (α) to all tokens. But obviously, some tokens in a sentence are “secure” (aligned), while others are “dangerous” (about to cause the model to produce misaligned content). Using the same amount of force to ‘push’ all tokens may either cause excessive intervention in secure tokens (which may affect fluency and usefulness), or insufficient intervention in dangerous tokens (which cannot effectively correct errors). The goal of the MAI module is to calculate an adaptive editing strength A (o \ ut) for each token currently being generated during inference. It perceives the risk of “misalignment” of a token from two dimensions:
+Dual channel misalignment assessment: evaluating the potential uncertainty level of tokens from two aspects: representing misalignment estimation and quantifying prediction uncertainty
+Dynamic intensity adjustment: adaptively calculate intervention intensity based on the degree of misalignment, with strong intervention for high-risk tokens and weak intervention for low-risk tokens.
In the end, the TAE method combined the two and achieved finer, more effective, and lower cost reasoning alignment interventions than previous methods, achieving significant improvements in multiple alignment dimensions such as authenticity, harmlessness, and fairness.
##Experimental results: significantly surpassing existing methods
The team selected three typical alignment dimensions of authenticity, harmfulness, and fairness to evaluate the alignment effectiveness of TAE:
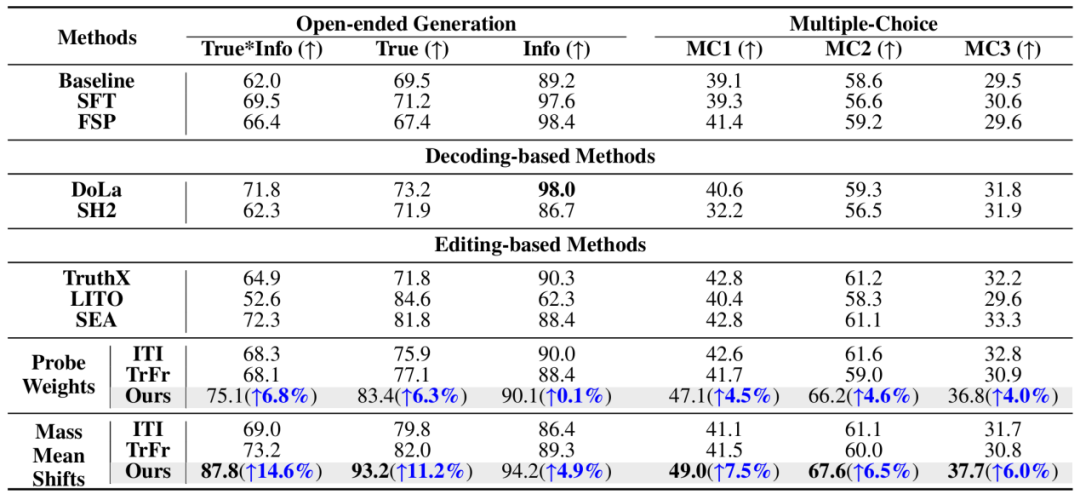
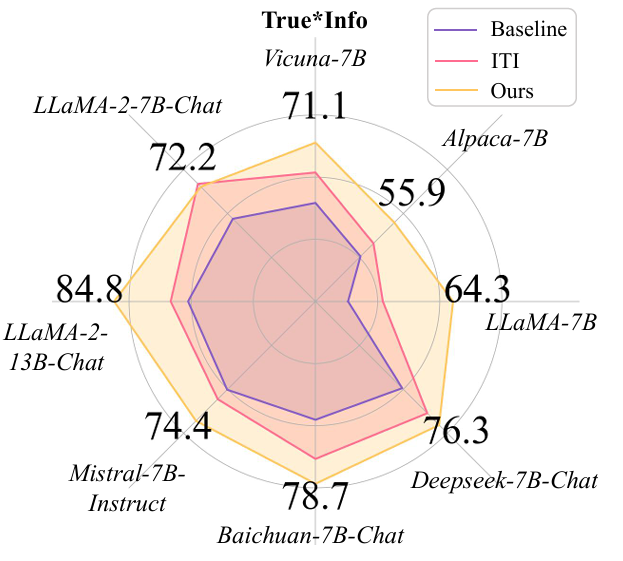
On the TruthfulQA dataset for evaluating authenticity, TAE achieved a True \ * Info score of 87.8% on LLaMA-3-8B Instruction, which is 14.6 percentage points higher than the previous best editing method (SEA: 73.2%) and 25.8 percentage points higher than the original baseline (62.0%).
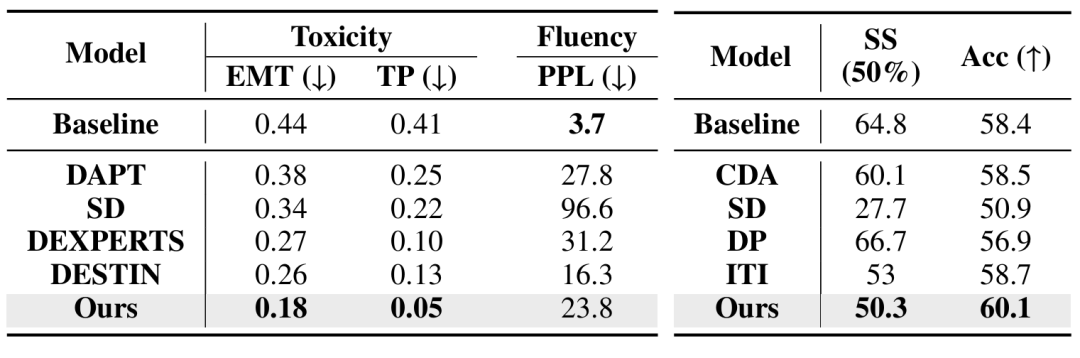
TAE also performed excellently in the RealToxicTropt of detoxification tasks, significantly reducing TP (probability of toxicity) from baseline 0.41 to 0.05, a decrease of nearly 90%, and outperforming all specialized detoxification baseline methods (such as DESTEIN: 0.13); On the fairness task dataset StereoSet, TAE significantly reduced the stereotype score (SS) from 64.8% of the baseline to 50.3%, greatly alleviating model bias and closest to the ideal unbiased state (50%).
Moreover, TAE has shown significant gains on different types and sizes of models, such as Llama2-7B Chat, Llama2-13B Chat, Alpaca-7B, and Mistral-7B.
*Paper link: https://openreview.net/pdf?id=43nuT3mODk *